


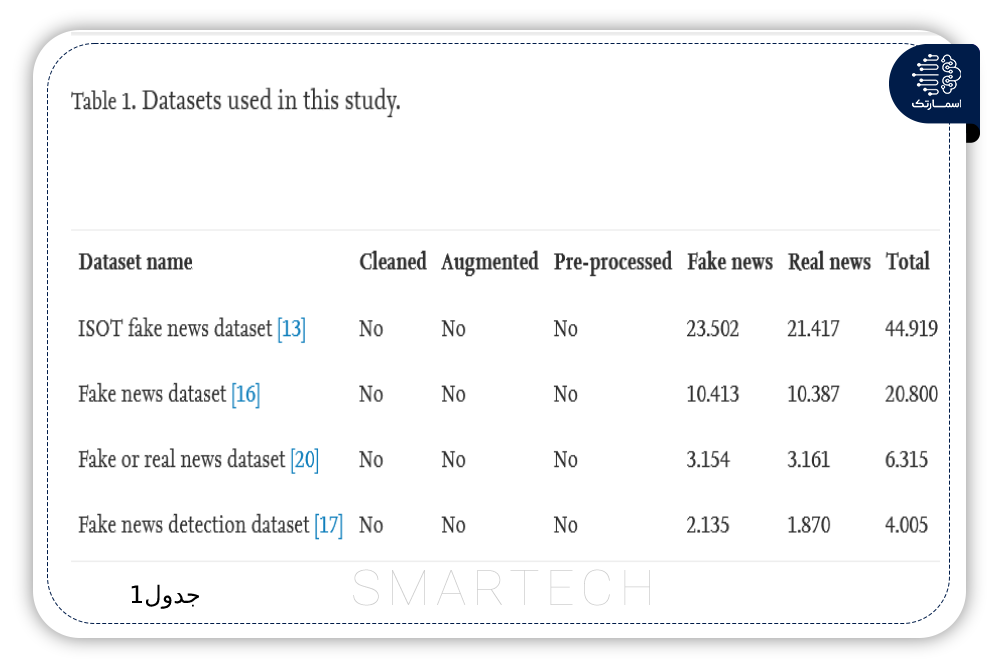
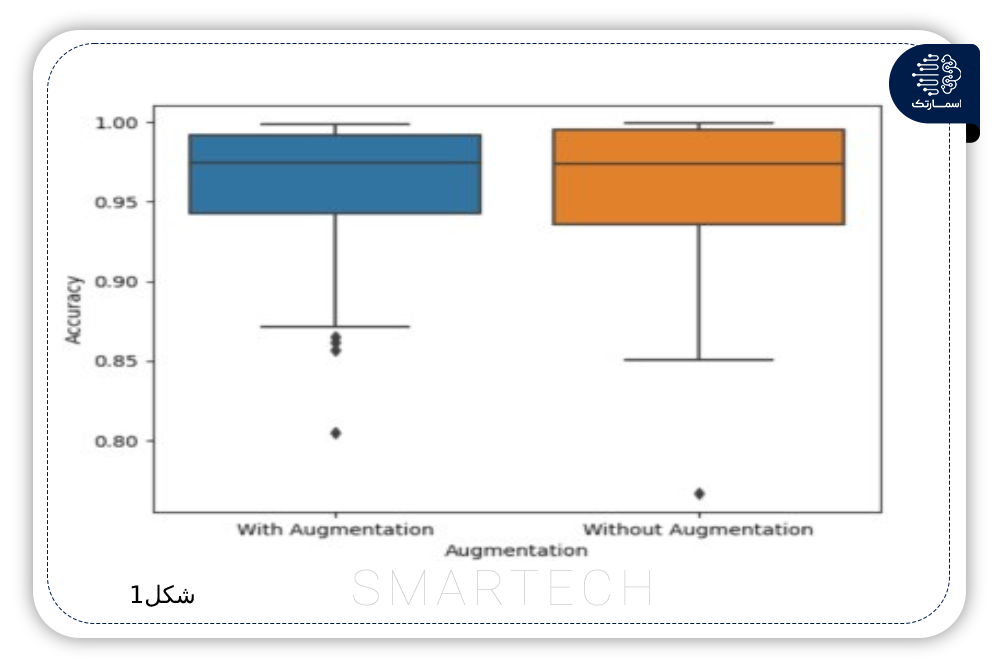
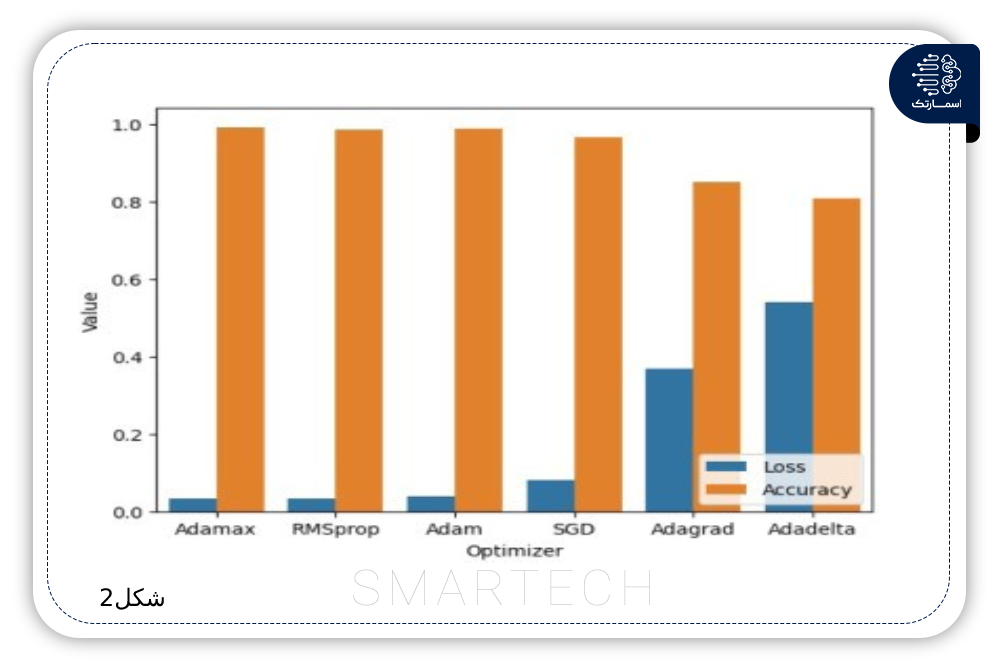
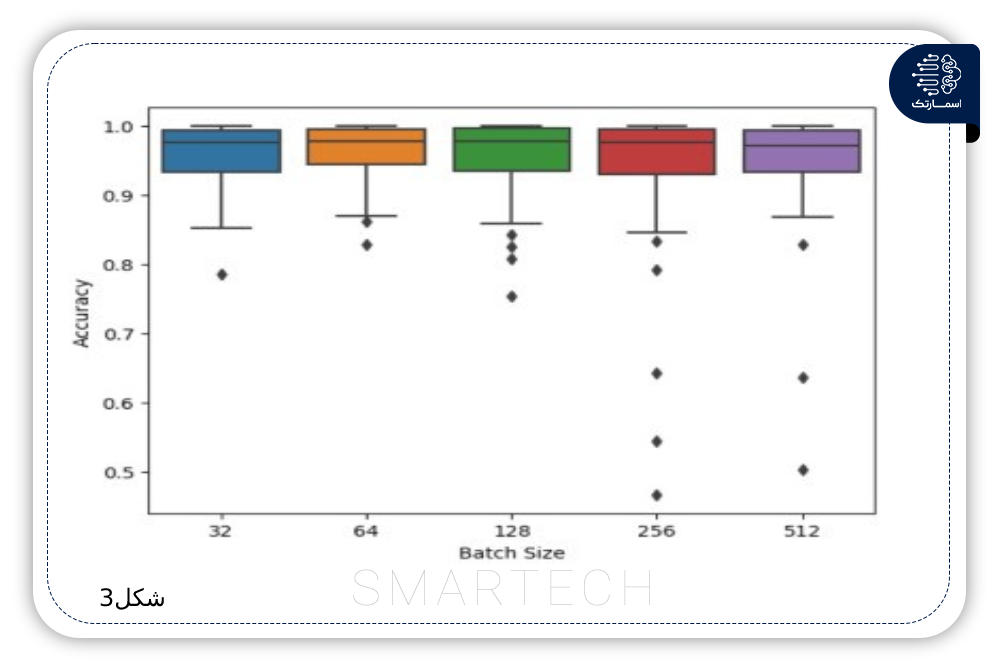
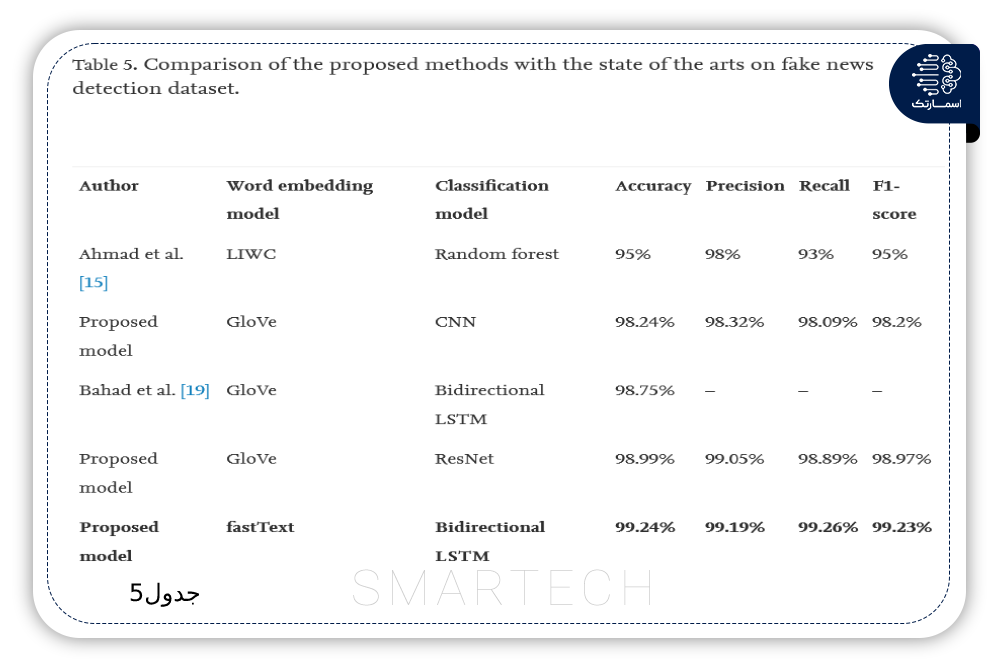
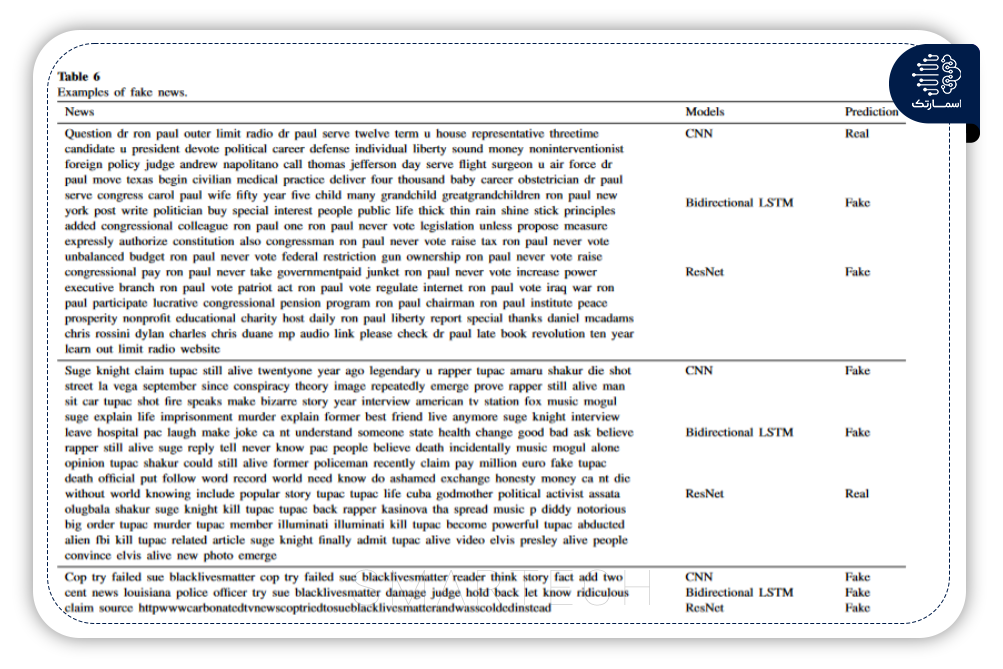
تشخیص اخبار جعلی با استفاده از روشهای مبتنی بر یادگیری عمیق CNN-RNN







دوره جامع هوش مصنوعی
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره هوش مصنوعی دیگر…

دوره کسب درآمد از هوش مصنوعی
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره همانطور که یادگیری…

دوره پردازش زبان طبیعی
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره ما انسان ها…

دوره بینایی ماشین
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره ما انسان ها…

دوره یادگیری عمیق
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره یادگیری عمیق زیرشاخهای…

دوره یادگیری ماشین
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره اگر بخواهیم به…

دوره پایتون و ریاضیات هوش مصنوعی
معرفی دوره چرا این دوره؟ پس از پایان دوره چرا اسمارتک سوالات متداول ثبت نام معرفی دوره این دوره 30…

وبینار هوش مصنوعی و هوش طبیعی
هوش مصنوعی و هوش طبیعی: یه عالمه فرصت و چالش!
همیشه دوست داشتی بدونی هوش مصنوعی چیه و چطوری کار میکنه؟تو این وبینار، با هوش مصنوعی و هوش طبیعی آشنا میشی و میفهمی که چه جوری میتونن زندگی و کارمون رو تغییر بدن.از فرصتهای جذاب هوش مصنوعی میشنوی و با چالشهای پیش روی اون آشنا میشی.پس یه فرصت به خودت بده و تو این وبینار شرکت کن!مطمئنم که پشیمون نمیشی








دیدگاهتان را بنویسید