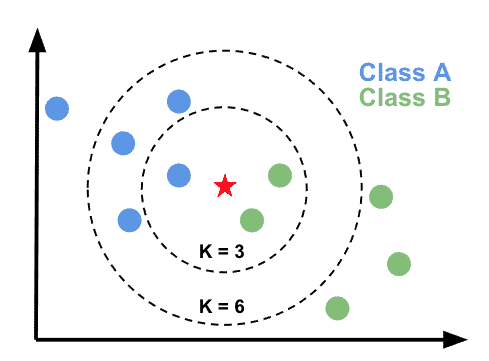
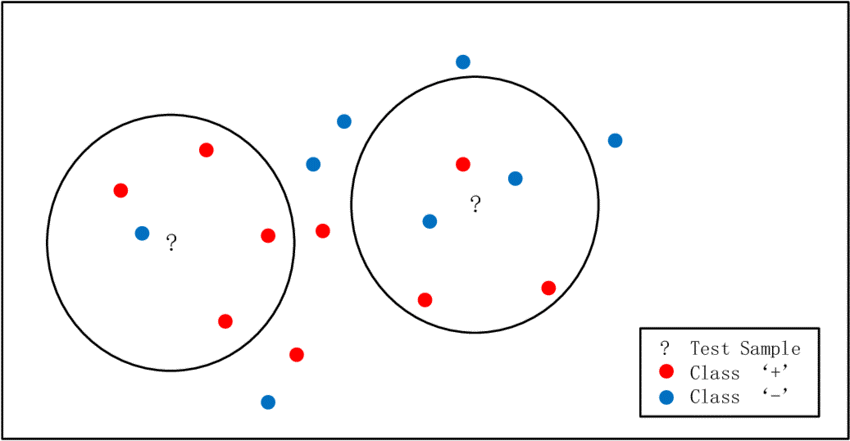
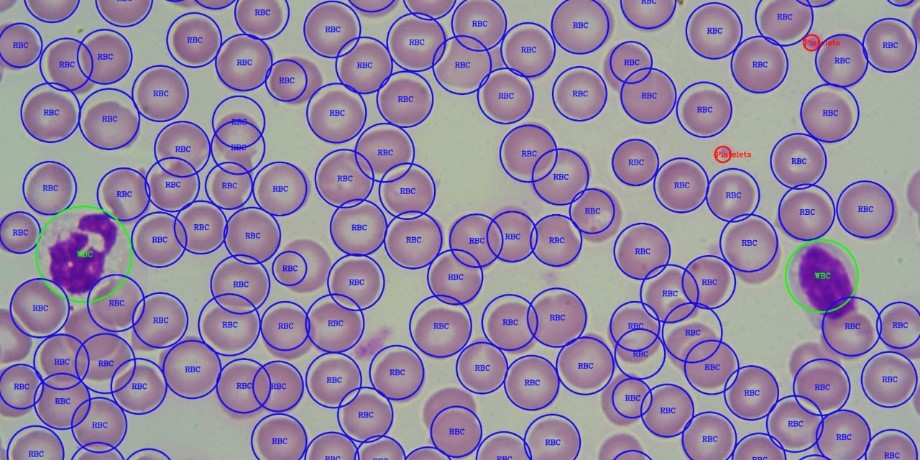
آموزش الگوریتم knn با تست خون

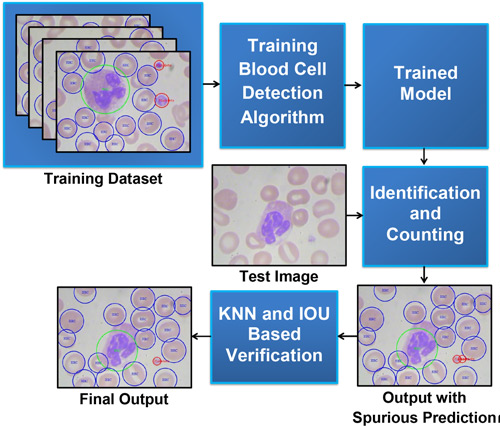
مطالب زیر را حتما مطالعه کنید






2 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.



به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.


شرکت خلاق در معاونت علمی و فناوری ریاست جمهوری





ممنون از این مقاله کاربردی
سایت خوب با مقالاتی بسیار بی نظیری دارین