در سال های اخیر، پیش بینی تراکم ترافیک منجر به یک حوزه تحقیقاتی رو به رشد، به ویژه یادگیری ماشینی هوش مصنوعی (AI) شده است. با معرفی داده های بزرگ توسط حسگرهای ثابت یا داده های وسایل نقلیه کاوشگر و توسعه مدل های جدید هوش مصنوعی در چند دهه اخیر، این حوزه تحقیقاتی به طور گسترده ای گسترش یافته است. پیش بینی تراکم ترافیک با هوش مصنوعی به ویژه پیش بینی تراکم ترافیک کوتاه مدت با ارزیابی پارامترهای مختلف ترافیک انجام می شود. بیشتر تحقیقات بر روی داده های تاریخی در پیش بینی تراکم ترافیک تمرکز دارند. این مقاله به طور سیستماتیک تحقیقات موجود انجام شده با استفاده از روشهای مختلف هوش مصنوعی، به ویژه مدلهای مختلف یادگیری ماشین را خلاصه میکند.
هوش مصنوعی و تراکم ترافیک
تراکم ترافیک تاثیر مستقیم و غیرمستقیم بر اقتصاد یک کشور و سلامت ساکنان آن دارد. تراکم ترافیک در سطح فردی نیز تأثیر می گذارد. از دست دادن زمان به ویژه در ساعات اوج مصرف، استرس های روحی و افزایش آلودگی ناشی از گرمایش جهانی نیز از عوامل مهم ناشی از ازدحام ترافیک است.
تضمین رشد اقتصادی و آسایش کاربران جاده دو شرط توسعه یک کشور است که بدون روان شدن ترافیک غیرممکن است. پیشبینی تراکم ترافیک، زمان لازم را در اختیار مسئولان قرار میدهد تا در تخصیص منابع برنامهریزی کنند تا سفر را برای مسافران راحت کند. مشکل پیشبینی تراکم ترافیک ،میتواند به عنوان تخمین پارامترهای مربوط به تراکم ترافیک در آینده کوتاهمدت، به عنوان مثال، 15 دقیقه تا چند ساعت با استفاده از روشهای مختلف هوش مصنوعی و با استفاده از دادههای ترافیک جمعآوریشده، تعریف شود.
معمولاً پنج پارامتر برای ارزیابی وجود دارد، از جمله حجم ترافیک، تراکم ترافیک، اشغال، شاخص تراکم ترافیک و زمان سفر در حین نظارت و پیشبینی ازدحام ترافیک. بسته به ماهیت داده های جمع آوری شده، انواع رویکردهای هوش مصنوعی برای ارزیابی پارامترهای تراکم استفاده می شود. این مقاله مدل ها و مزایا و معایب آنها را مورد بحث قرار می دهد.
آیا پیش بینی تراکم ترافیک با هوش مصنوعی امکان پذیر است؟
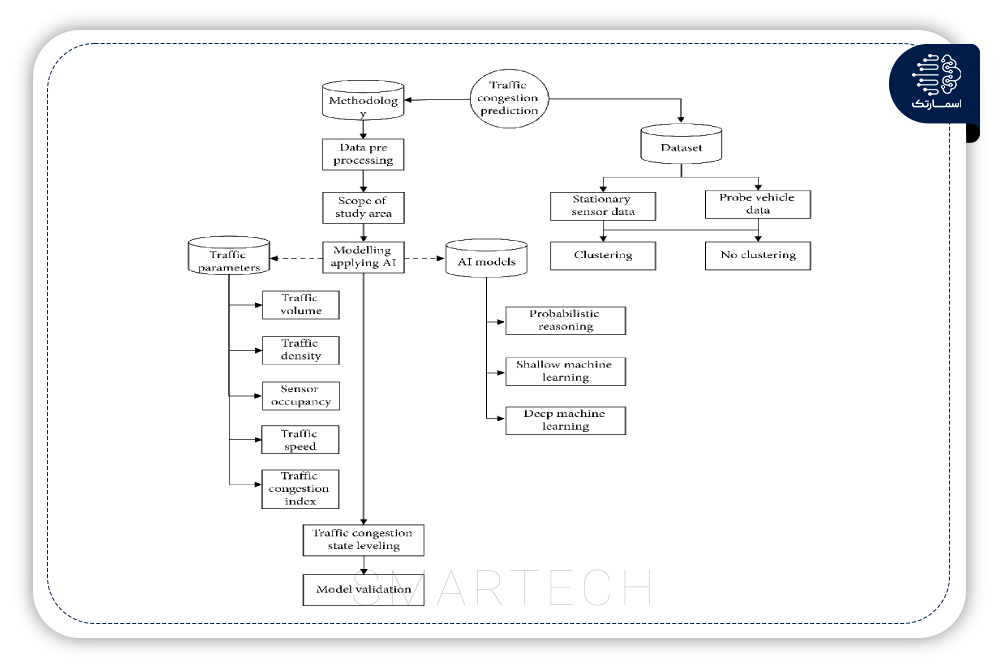
پیش بینی تراکم ترافیک دارای دو مرحله اساسی جمع آوری داده ها و توسعه مدل پیش بینی است. پس از جمع آوری داده ها، پردازش داده ها نقشی حیاتی برای آماده سازی مجموعه داده های آموزشی و آزمایشی ایفا می کند. پس از توسعه مدل، آن را با مدل های پایه دیگر تایید و نتایج واقعی را پایه گذاری می کند. شکل زیر مولفه های کلی مطالعات پیش بینی تراکم ترافیک را نشان می دهد. این شاخه ها بیشتر به زیر شاخه های خاص تری تقسیم شدند و در بخش های بعدی مورد بحث قرار می گیرند.
اگر به راه اندازی و توسعه کسب و کار مبتنی بر هوش مصنوعی علاقه دارید دوره زیر مخصوص شماست:
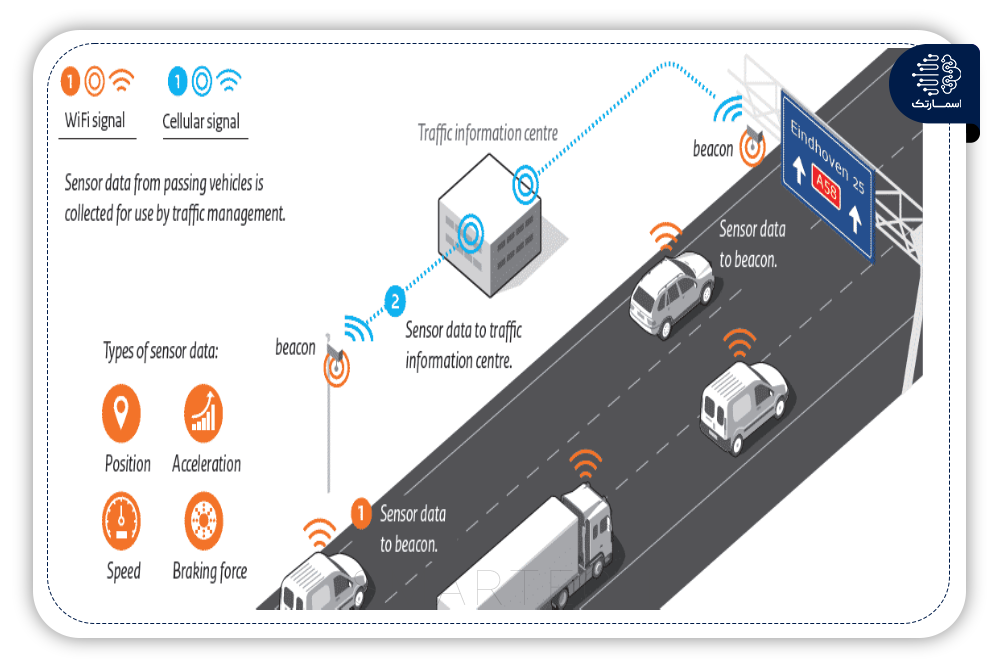
مجموعه داده های ترافیک مورد استفاده در مطالعات مختلف را می توان به طور عمده به دو دسته تقسیم کرد، از جمله داده های ثابت و Probe. داده های ثابت شامل داده های حسگر و دوربین های ثابت و داده های کاوشگری داده های GPS نصب شده بر روی وسایل نقلیه بودند.
حسگرهای ثابت به طور مداوم دادههای مکانی و زمانی ترافیک را ضبط میکنند. با این حال، عملکرد سنسور ممکن است در هر زمان قطع شود. متخصصان باید همیشه هنگام برنامه ریزی با استفاده از این داده ها، این خرابی موقت سنسور را در نظر بگیرند. مزیت دادههای سنسور این است که هیچ گونه سردرگمی در محل وسایل نقلیه وجود ندارد.
مشاوره رایگان مسیریادگیری هوش مصنوعی
مقالات
از سوی دیگر، دادههای Probe این مزیت را دارند که کل شبکه راه را پوشش میدهند. یک شبکه از جاده های ساختاری متفاوتی تشکیل شده است. بنابراین، مطالعات، به ویژه آنهایی که منطقه وسیع شبکه را در نظر گرفتند، از داده های Probe استفاده کردند. با این حال، گاهی اوقات داده های Probe نوسانات قابل توجهی را نشان میدهد. علاوه بر این، تطبیق نقشه معمولاً برای داده های Probe ضروری است. اما دادهها میتوانند این محدودیت را به حداقل برسانند. دادههای Probeجمع آوری شده ازیک شهررا نمیتوان مستقیماً برای مدل سازی شبکههای شهری دیگراستفاده کرد. با این حال، یک مدل تعمیم یافته با استفاده از دادههای Probe میتواند برای شهرهای مختلف تولید شود.
سایر منابع داده، به عنوان مثال، داده های سیستم عوارض و داده های ارائه شده توسط مسئولان حمل و نقل، داده های قابل اعتماد بیشتری را اضافه می کنند زیرا منابع قابل اعتماد هستند. با این حال، در بسیاری از مواقع، حوزه مطالعه نیاز به تنظیم دارد، زیرا در بیشتر موارد، اطلاعات جاده دارای عوارض در دسترس نیست. ردیابی حرکات تلفن همراه بدون نقض حریم خصوصی نیز می تواند منبع داده باشد. با این حال، تعیین ناهمگونی توزیع خودرو از این مجموعه داده، اگر غیرممکن نباشد، دشوار خواهد بود. علاوه بر این، به دلیل حرکت عابران پیاده یا دوچرخه سواران از طریق پیاده رو، اگر مدل سازی برای یک شبکه جاده ای انجام شود، ممکن است موارد پرت زیادی در مجموعه داده وجود داشته باشد. داده های جمع آوری شده از یک پرسشنامه برای عموم مردم/رانندگان ممکن است یک نتیجه گمراه کننده ارائه کند.
اگر دوست دارید وارد دنیای هوش مصنوعی شوید و یک مسیر جامع را دنبال کنید دوره های زیر مخصوص شماست:
الگوریتم های خوشه بندی هوش مصنوعی و تراکم ترافیک
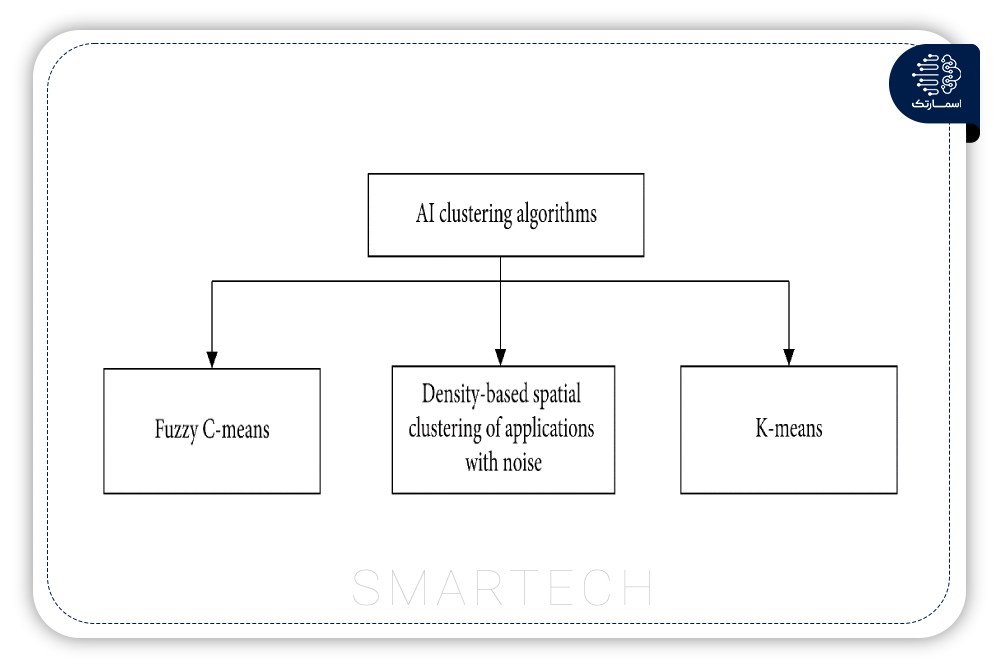
برخی از مطالعات از خوشهبندی دادههای بهدستآمده قبل از اعمال مدلهای تراکم اصلی پیشبینی استفاده میکنند. این تکنیک مدل سازی ترکیبی برای تنظیم دقیق مقادیر ورودی و استفاده از آنها در مرحله آموزش اعمال می شود. در شکل زیر مدلهای خوشهبندی هوش مصنوعی رایج در این زمینه تحقیقاتی را نشان میدهد. در این قسمت مدل ها به اختصار توضیح داده شده است.
C-Means (FCM) Fuzzyیک تکنیک خوشهبندی غیر قطعی محبوب در داده کاوی است. در تحقیقات مهندسی ترافیک، تشخیص الگوی ترافیک نقش مهمی ایفا می کند. علاوه بر این، این مطالعات اغلب با محدودیت دادههای گم شده یا ناقص روبرو هستند. برای مقابله با این محدودیتها، FCM به یک تکنیک خوشهبندی رایج تبدیل شده است. مزیت این رویکرد این است که برخلاف روشهای اصلی خوشهبندی C-means، میتواند بر مسئله به دام افتادن در بهینه محلی غلبه کند.
اگر به کسب تخصص در حوزه هوش مصنوعی علاقه دارید دوره زیر مخصوص شماست:
با این حال، FCM نیاز به تنظیم یک عدد خوشه از پیش تعریف شده دارد، که همیشه در هنگام برخورد با داده های انبوه بدون دانش قبلی از بعد داده ممکن نیست. علاوه بر این، این مدل با افزایش اندازه داده ها از نظر محاسباتی گران می شود. مطالعات مختلف FCM را با بهبود محدودیتهای آن با موفقیت به کار گرفتهاند. برخی از مطالعات مقدار شاخص فازی را برای هر اجرای الگوریتم FCM تغییر دادند ، برخی شاخص Davies-Bouldin (DB) را محاسبه کردند، در حالی که برخی دیگر از الگوریتم خوشه بندی K-means استفاده کردند.
خوشهبندی K-means یک الگوریتم مؤثر و نسبتاً انعطافپذیر در هنگام برخورد با مجموعه دادههای بزرگ است. این یک الگوریتم یادگیری ماشین بدون نظارت محبوب است. بسته به ویژگی ها، تعداد خوشه از دو تا 50 متغیر بود. مانند FCM، خوشهبندی K-means به یک عدد خوشه از پیش تعریفشده و انتخاب مراکز خوشه اصلی K نیاز دارد. برای تعریف مقدار از GAP وجعبه ابزار WEKA استفاده شد.
برای مجموعه داده های بزرگ، از آنجایی که توزیع نمونه در ابتدا ناشناخته است، انجام این دو الزام همیشه ممکن نیست. چند مطالعه از خوشه بندی K-means تطبیقی برای غلبه بر محدودیت ها استفاده کردند و الگو را با استفاده از تجزیه و تحلیل مؤلفه اصلی (PCA) بهره برداری کردند.
DBSCAN بیشتر یک برنامه خوشه بندی عمومی در یادگیری ماشین و داده کاوی است. این روش بر محدودیت FCM برای از پیش تعریف کردن تعداد خوشه غلبه می کند. میتواند بهطور خودکار اشکال خوشهای دلخواه ایجاد کند که توسط خوشههایی با ویژگیهای مختلف احاطه شدهاند و به راحتی میتواند موارد پرت را تشخیص دهد.
با این حال، برای از پیش تنظیم کردن به دو پارامتر نیاز دارد. یک روش مناسب تعیین پارامتر، مانند روش آزمون و خطا و قضاوت انسانی مدل را از نظر محاسباتی گران میکند و به درک روشنی از مجموعه داده نیاز دارد.
چندین مدل سری زمانی و الگوریتم های یادگیری ماشین کم عمق (SML) از رویکرد خوشه بندی استفاده کرده اند. با این حال، الگوریتمهای یادگیری عمیق میتوانند دادههای ورودی را در لایههای مختلف مدل پردازش کنند، بنابراین ممکن است از قبل نیازی به خوشهبندی نداشته باشند.
روش شناسی کاربردی برای کنترل ترافیک با هوش مصنوعی
جریان ترافیک ترکیبی پیچیده از ناوگان ترافیکی ناهمگن است. بنابراین، مدلسازی پیشبینی الگوی ترافیک میتواند یک رویکرد پیشبینی تراکم آسان و کارآمد باشد. با این حال، بسته به ویژگی ها و کیفیت داده ها، کلاس های مختلف هوش مصنوعی در مطالعات مختلف استفاده می شود.
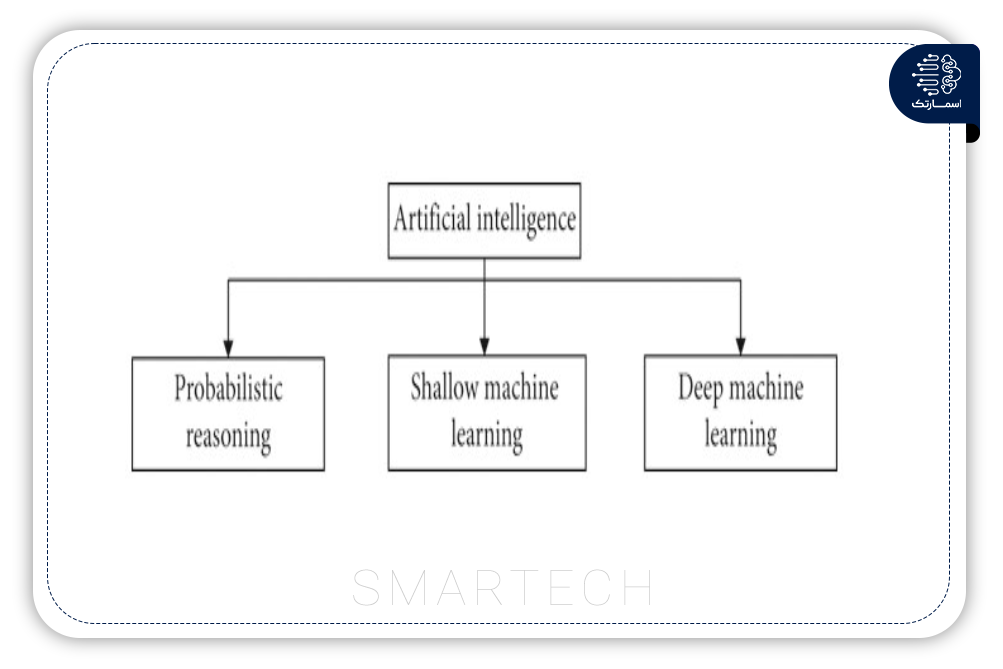
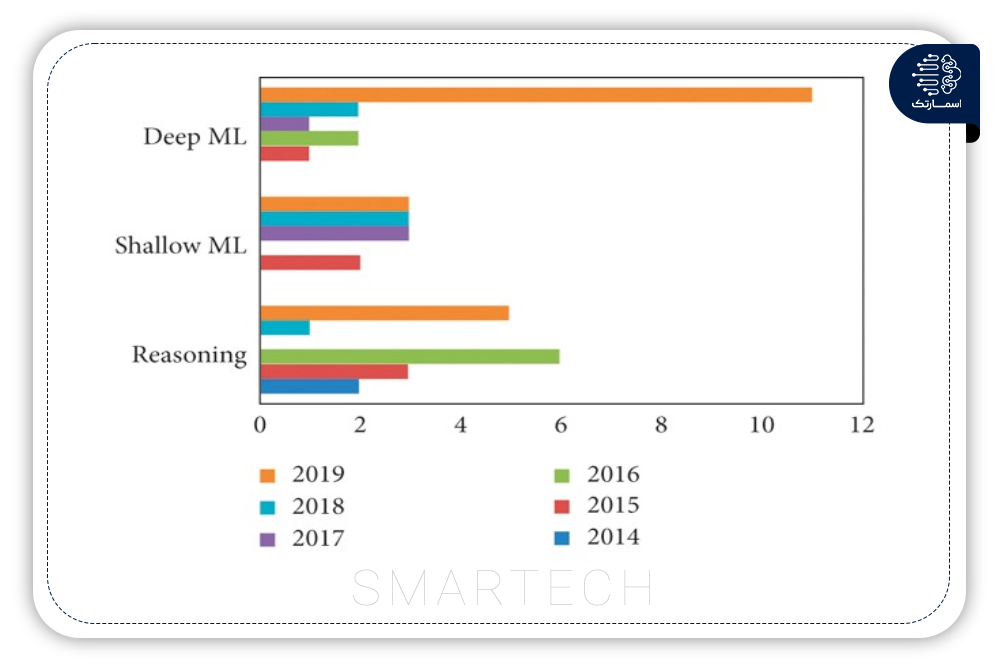
شکل 3 شاخه های اصلی – استدلال احتمالی و یادگیری ماشین (ML) را نشان می دهد. یادگیری ماشینی از هردوالگوریتم یادگیری کم عمق و عمیق تشکیل شده است. با این حال، با پیشرفت این مقاله، این بخش ها به الگوریتم های دقیق تقسیم شدند.
تعمیم مطالعات پیشبینی تراکم ترافیک با استفاده از مدلهای مختلف ساده نیست. عوامل مشترک همه مقالات شامل محدوده مورد مطالعه، افق جمع آوری داده ها، پارامتر پیش بینی شده، فواصل پیش بینی و روش اعتبار سنجی است. اکثر مقالات بخش corridor را به عنوان منطقه مورد مطالعه در نظر گرفتند . سایر مناطق شامل شبکه ترافیک ، جاده کمربندی و جاده شریانی بود. افق جمع آوری داده ها از 2 سال تا کمتر از یک روز در مطالعات متفاوت بود.
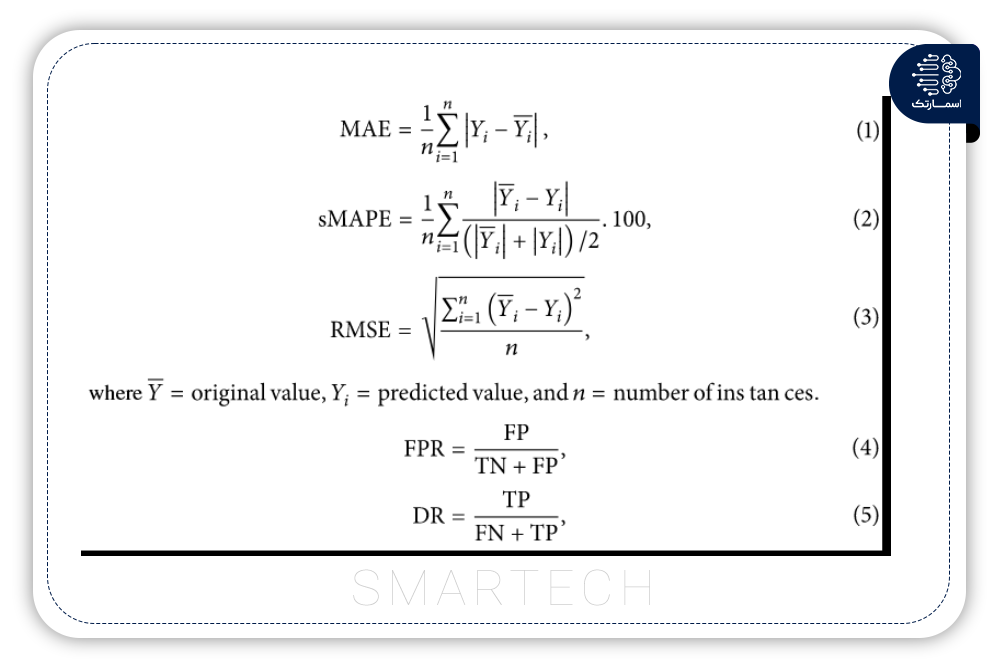
تخمین تراکم با پیشبینی پارامترهای جریان ترافیک انجام میشود، به عنوان مثال، سرعت ترافیک ، تراکم، سرعت و شاخص تراکم CI)).مطالعاتی که نتایج خود را با مقدار صدق زمین یا با سایر مدلهای مورد استفاده مقایسه کردند میانگین خطای مطلق (MAE) (معادله (1))، میانگین درصد مطلق خطای متقارن (sMAPE) (معادله (2))، MAPE، ریشه میانگین مربع خطا (RMSE) (معادله (3))، نرخ مثبت کاذب (FPR) (معادله (4))، و نرخ تشخیص (DR) (معادله (5)).
بسیاری از مطالعات از SUMO برای اعتبارسنجی مدل های خود استفاده کردند:
که در آن FP، TN، FN و TP به ترتیب نشان دهنده مثبت کاذب، منفی درست، منفی کاذب و مثبت واقعی هستند.
بقیه این بخش روش شناسی را که متخصصان در مطالعات به کار برده اند مورد بحث قرار خواهد داد.
A. استدلال احتمالی و انواع مدل ها
استدلال احتمالی بخش مهمی از هوش مصنوعی است. برای مقابله با حوزه دانش و استدلال نامطمئن استفاده می شود. انواعی از این الگوریتمها معمولاً در مطالعات پیشبینی تراکم ترافیک استفاده میشوند. مطالعات مورد بحث در زیراستدلال احتمالی در شکل زیر نشان داده شده است.
1- منطق فازی
Zadehیک مدل متداول در پیشبینی تراکم ترافیک پویا است زیرا به جای نتایج باینری اجازه میدهد مبهم باشد. در این روش، چندین تابع عضویت توسعه مییابد که نشان دهنده درجه صدق هستند. با گذشت زمان، داده های ترافیک پیچیده و غیرخطی می شوند. به دلیل توانایی آن برای مقابله با عدم قطعیت در مجموعه داده، منطق فازی در مطالعات پیشبینی تراکم ترافیک رایج شده است.
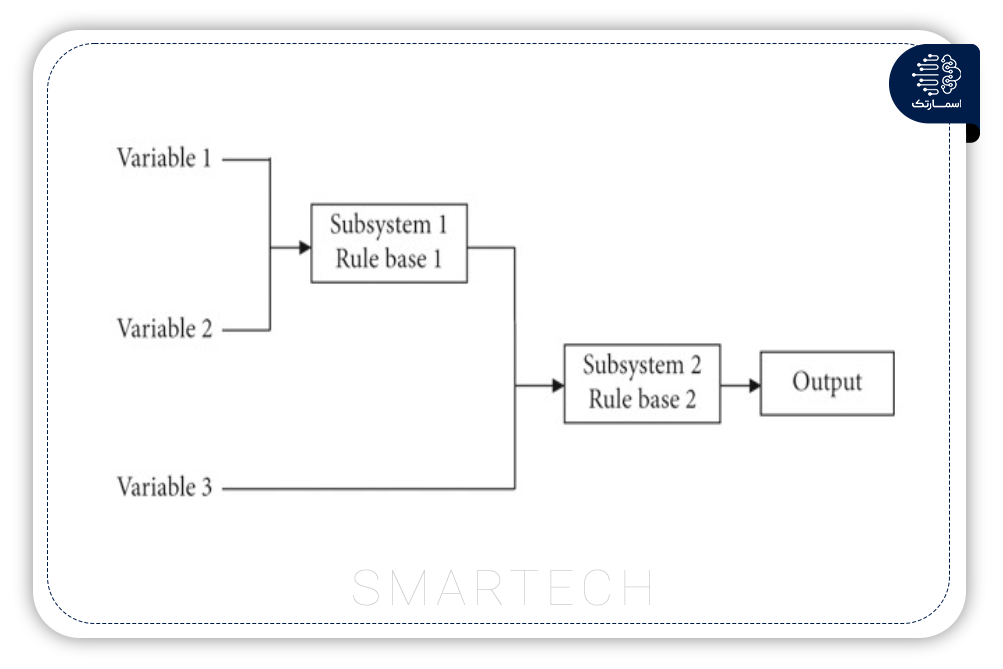
یک سیستم فازی از چندین مجموعه فازی تشکیل شده است که از توابع عضویت ساخته شده است. معمولاً سه شکل کدگذاری برای توابع عضویت (MF) ورودی وجود دارد: مثلثی، ذوزنقه ای و تابع گاوس. سیستم مبتنی بر قوانین فازی (FRBS) رایج ترین سیستم منطق فازی در تحقیقات مهندسی ترافیک است.
این شامل چندین قانون IF-THEN است که به طور منطقی متغیرهای ورودی را با خروجی مرتبط می کند. این می تواند به طور موثر با پیچیدگی های ناشی از موقعیت های ترافیکی دنیای واقعی با نشان دادن آنها در قوانین ساده مقابله کند. این قوانین روابط بین حالات ترافیکی مختلف را برای تشخیص وضعیت ترافیک حاصل ترکیب می کند. با این حال، با رشد پیچیدگی دادهها، تعداد کل قوانین نیز افزایش مییابد و دقت کل سیستم را کاهش میدهد و در نتیجه آن را از نظر محاسباتی گران میکند.
. برای مدیریت بهتر این مشکل، از دو نوع کنترل منطق فازی استفاده می شود. در کنترل سلسله مراتبی (HFRBS)، با توجه به اهمیت، متغیرهای ورودی ، مرتب شده و از MFها استفاده می شود. شکل 5 یک ساختار ساده HFRBS را نشان می دهد. MFها با استفاده از الگوریتمهای مختلف ، به عنوان مثال، الگوریتم ژنتیک (GA) ، الگوریتم ژنتیک ترکیبی (GA)، و آنتروپی متقابل (CE) بهینه میشوند که عملکرد یادگیری قواعد واضح تکاملی (ECRL) و یادگیری قواعد فازی تکاملی (EFRL) را برای پیشبینی تراکم ترافیک جادهای مقایسه میشوند .مشاهده شد که مدلهای ECRL از نظر دقت متوسط و عدم وجود قوانین، بهتر ازEFRL عمل کردند، اما از نظر محاسباتی گران بودند.
مدل Takagi-Sugeno-Kang (TSK) (FRBS)یکی از مدل های فازی ساده به دلیل قابلیت پردازش ریاضی آن است. میانگین وزنی ، خروجی این مدل را محاسبه می کند. مدل ساده دیگر FRBS مدل Mamdaniاست. خروجی این مدل یک مجموعه فازی است که نیاز به فازی سازی دارد که زمان بر است. به دلیل قابلیت تفسیر خوب، می تواند دقت مدل های زبانی فازی را بهبود بخشد.
چند مطالعه از این روش برای ترکیب پارامترهای ناهمگن استفاده کردند .مدل TSK روی بهبود تفسیرپذیری یک مدل فازی دقیق کار می کند وبرای مشخصه های محاسبات سریع آن اعمال می شود.
ارزیابی جامع فازی (FCE) از اصل تبدیل فازی و حداکثر درجه عضویت استفاده می کند. این مدل از چندین لایه تشکیل شده است که یک روش ارزیابی عینی مفید برای ارزیابی تمامی عوامل مرتبط می باشد. تعداد لایه ها به پیچیدگی هدف و تعداد عوامل بستگی دارد.
به غیر از GA و PSO، الگوریتم Ant Colony Optimization (ACO) نیز توسط Daissaoui در سیستم منطق فازی معرفی شد. آنها تئوری یک شهر هوشمند را ارائه کردند که در آن داده های GPS هر وسیله نقلیه به عنوان یکPheromone در نظر گرفته می شد که مطابق با مفهوم ACO است.
هدف،پیش بینی تراکم ترافیک یک دقیقه جلوتر از اطلاعات (Pheromone) ارائه شده توسط خودروهای گذشته بود. با این حال، مقاله هیچ نتیجه ای در مورد پشتیبانی از مدل ارائه نمی دهد.
همانطور که قبلاً بحث شد، با توسعه الگوریتمهای بهینهسازی، بهینهسازی توابع عضویت سیستم منطق فازی متنوع میشود. با گذشت زمان، ساده ترین شکل FRBS-TSK به دلیل قابلیت تفسیر خوب آن محبوب شده است.
سیستم منطق فازی تنها مدل استدلال احتمالی است که می تواند نتیجه ای بیش از حالت تراکم/غیرازدحام وضعیت ترافیک داشته باشد. این یکی از مزایای اصلی است که این روش را محبوب کرده است. با این حال، هیچ مطالعه ای هیچ منطق معقولی برای انتخاب تابع عضویت ارائه نکرده است که محدودیت قابل توجهی در مدل های منطق فازی است.
2- مدل مارکوف پنهان
مدل پنهان مارکوف (HMM) ترکیبی از ویژگیهای تصادفی فرآیند مارکوف و ویژگیهای گسسته زنجیرههای مارکوف است. این یک تکنیک تشخیص رویداد تصادفی و سری زمانی است. برخی از مطالعات از مدل زنجیره مارکوف برای تشخیص الگوی ترافیک در طول پیشبینی تراکم استفاده کردهاند . ضریب همبستگی پیرسون (PCC) معمولاً در بین پارامترها در طول ساخت الگو اعمال می شود.
در مهندسی ترافیک، به ویژه هنگام استفاده از داده های وسیله نقلیه Probe، HMM در تطبیق نقشه بسیار مفید است.
HMM دقت را در انتخاب الگوی ترافیک یا نقطه ترافیک نشان می دهد. این مزیت را دارد که می تواند با داده ها با مقادیر پرت برخورد کند. با این حال، به نظر می رسد نقاط با فاصله نمونه برداری کوتاه به خوبی مطابقت داشته باشند، و فواصل طولانی و داده های Probe مشابه بالاتر دقت مدل را کاهش دهد. مطالعات عدم تطابق قابل توجهی را برای مجموعه داده های فواصل نمونه برداری طولانی و شبکه های جاده ای مشابه پیدا کرده اند.
سیستم ردیابی GPS به طور گسترده در این دوره از ماهواره توسعه یافته است. بنابراین، ساخت مدلسازی HMM در حال حاضر برای تطبیق نقشه مرتبط تر است.
3- توزیع گاوسی
ثابت شده است که فرآیندهای گاوسی یک ابزار موفق برای مشکلات رگرسیون هستند. به طور رسمی، یک فرآیند گاوسی مجموعه ای از متغیرهای تصادفی است که هر تعداد محدودی از آنها از توزیع قبلی گاوسی مشترک تبعیت می کند. برای رگرسیون، تابعی که باید تخمین زده شود، توسط یک توزیع گاوسی بیبعدی تولید میشود و خروجیهای مشاهدهشده توسط نویز گاوسی افزودنی آلوده میشوند.
در برخی از مطالعات از توزیع گاوسی استفاده شد که مشاهده میشود مدل توزیع گاوسی کاربرد مفیدی در کاهش اعداد ویژگیها بدون به خطر انداختن کیفیت نتایج پیشبینی یا تخمین خطای مکان در هنگام استفاده از دادههای GPS دارد. توزیع گاوسی همچنین در پیشبینی حجم ترافیک ، ایمنی ترافیک و تنوع توزیع سرعت ترافیک اعمال میشود.
4- شبکه بیزی
یک شبکه بیزی (BN)، که به عنوان مدل علّی نیز شناخته می شود، یک مدل گرافیکی جهت دار برای نمایش استقلال های شرطی بین مجموعه ای از متغیرهای تصادفی است. این ترکیبی از نظریه احتمالات و نظریه گراف است و ابزاری طبیعی برای مقابله با دو مسئلهای است که از طریق ریاضیات کاربردی و مهندسی عدم پیچیدگی و قطعیت رخ میدهند
Asencio-Cortés مجموعه ای از هفت الگوریتم یادگیری ماشین برای محاسبه پیش بینی تراکم ترافیک اعمال کرد. این روش به عنوان یک مسئله طبقه بندی باینری با استفاده از الگوریتم HIOCC توسعه داده شد. سه مورد از این الگوریتم ها (C4.5، FURIA و BN) می توانند مدل های قابل تفسیردانش قابل مشاهده را تولید کنند.
مجموعه ای از الگوریتم های یادگیری ترکیبی برای بهبود نتایج بدست آمده از این مدل های پیش بینی استفاده شد. این الگوریتمهای گروهی شامل بسته بندی، تقویت (AdaBoost M1)، انباشته کردن، و انتخاب آستانه احتمال (PTS) بود.بعد از اعمال الگوریتمهای گروهی در دقت BN بهبود ایجاد شد
در مطالعهای دیگرBN را برای تعیین عواملی که بر شروع ازدحام در بخشهای مختلف جاده تأثیر میگذارند، اعمال کردند. مدل توسعه یافته این مطالعه چارچوبی برای ارزیابی رتبه بندی سناریوهای مختلف و اولویت بندی ارائه می دهد.
دیده میشود که شبکه بیزی با الگوریتمهای ترکیبی یا اصلاحشده ، به عنوان مثال، سایر بخشهای حملونقل، پیشبینی جریان ترافیک و تخمین پارامتر در تقاطع سیگنالدار بهتر عمل میکند .
جدول 1 روش ها و پارامترهای مختلف مورد استفاده در مطالعات مختلفی را که تاکنون مورد بحث قرار داده ایم، خلاصه می کند.
B. یادگیری ماشین کم عمق
الگوریتم های یادگیری ماشینی کم عمق (SML) شامل الگوریتم های سنتی و ساده ML هستند.الگوریتم های SML نمی توانند ویژگی ها را از ورودی استخراج کنند و ویژگی ها باید از قبل تعریف شوند. آموزش مدل فقط پس از استخراج ویژگی قابل انجام است. الگوریتم های SML و کاربرد آنها در مطالعات تراکم ترافیک در این بخش مورد بحث قرار گرفته ودرشکل زیر نشان داده است.
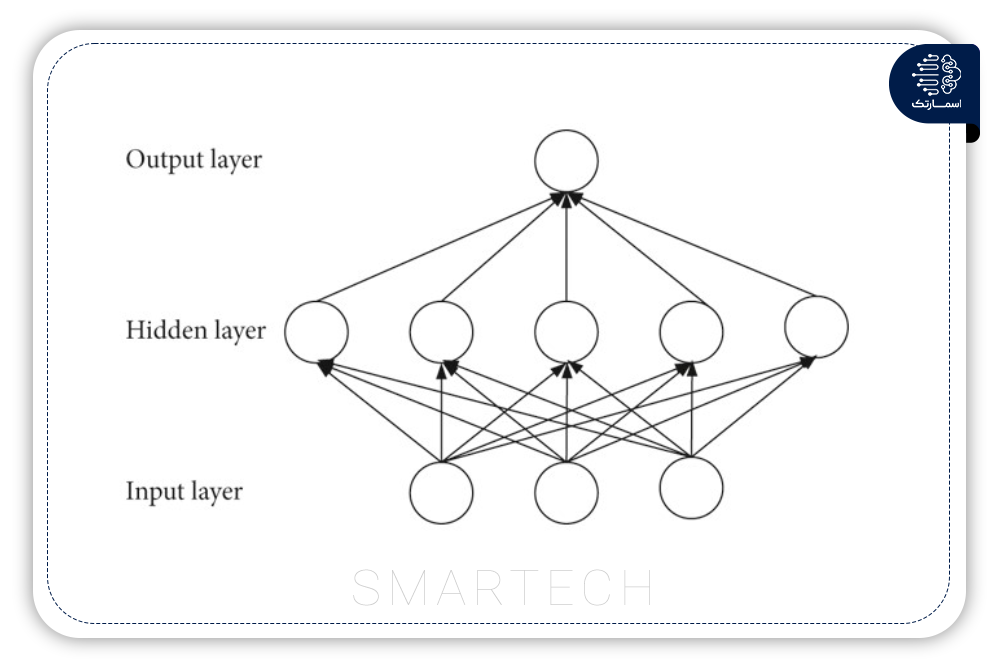
1- شبکه های عصبی مصنوعی
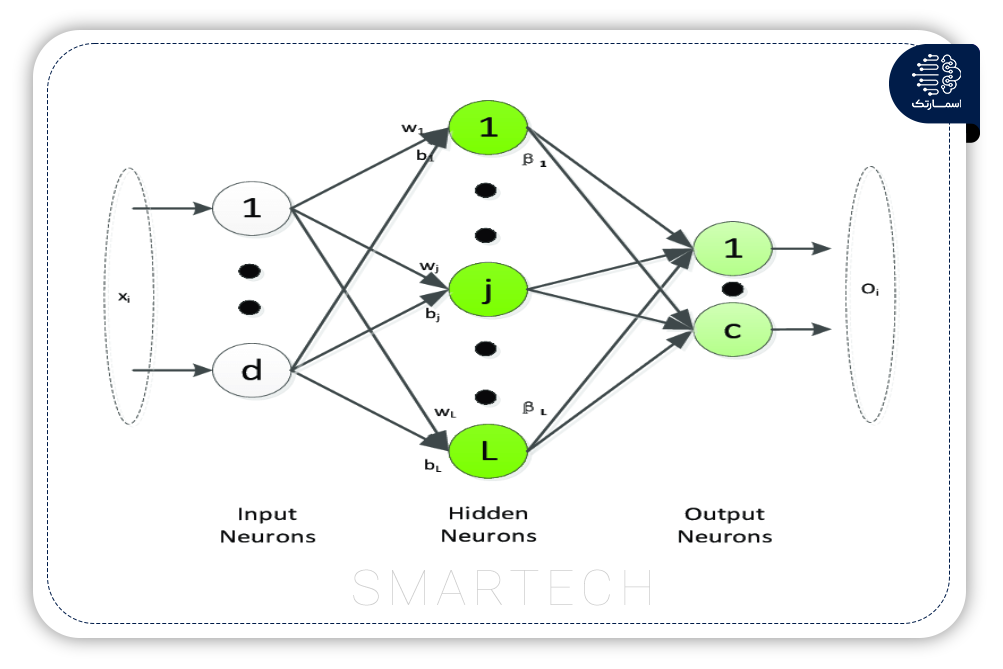
شبکه عصبی مصنوعی (ANN) با تقلید از عملکرد مغز انسان برای حل مسائل مختلف غیرخطی توسعه داده شد. این یک مدل ریاضی یا محاسباتی مرتبه اول است که از مجموعه ای از پردازنده ها یا نورون های به هم پیوسته تشکیل شده است. به دلیل اجرای آسان و توانایی پیش بینی کارآمد، ANN در زمینه تحقیقات پیش بینی تراکم ترافیک محبوب شده است.
شبکه Hopfield، شبکه feedforward و backpropagation نمونه هایی از ANN هستند. شبکه عصبی پیشخور (FNN) ساده ترین شبکه NN است که داده های ورودی به لایه پنهان و از آنجا به لایه خروجی می رود. شبکه (BPNN) متشکل از تنظیم feedforward و وزن لایه ها است و رایج ترین شبکه عصبی کاربردی در مدیریت حمل و نقل است.
ANN یک مدل یادگیری ماشینی مفید است که ساختاری انعطاف پذیر دارد. نورون های لایه را می توان با توجه به داده های ورودی تطبیق داد و یک مدل کلی را می توان برای انواع مختلف جاده با استفاده از مزیت توانایی ضبط غیرخطی شبکه عصبی مصنوعی توسعه داد و اعمال کرد. با این حال، ANN به مجموعه دادههای بزرگتری نسبت به مدلهای استدلال احتمالی نیاز دارد، که منجر به پیچیدگی بالا میشود.
ANN پتانسیل زیادی در تجزیه و تحلیل پارامترهای متنوع نشان می دهد. ANN تنها مدلی است که اخیرا برای تحلیل رفتار راننده برای تراکم ترافیک استفاده شده است. ANN در همه بخشهای پیشبینی جریان ترافیک ، کنترل ازدحام ، خستگی راننده و سر و صدای خودرو محبوب است.
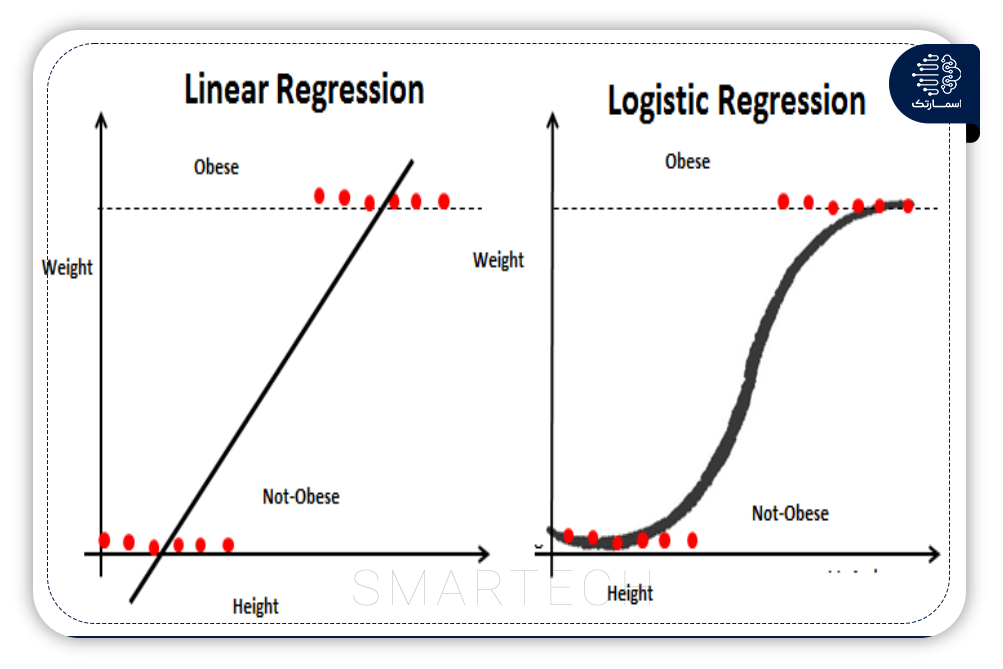
2- مدل رگرسیون
رگرسیون یک الگوریتم ML با نظارت آماری است. این مقدار خروجی عدد واقعی پیش بینی شده را بر اساس متغیر عددی ورودی مستقل مدل می کند. مدل های رگرسیون را می توان بر اساس تعداد متغیرهای ورودی بیشتر تقسیم کرد. ساده ترین مدل رگرسیون، رگرسیون خطی با یک ویژگی ورودی است. هنگامی که تعداد ویژگی افزایش می یابد، مدل رگرسیون چندگانه تولید می شود.
مدلهای رگرسیون شامل برخی ضرایب پنهان است که در مرحله آموزش تعیین میشوند. کاربردی ترین مدل رگرسیون، میانگین متحرک یکپارچه اتورگرسیو (ARIMA) است. ARIMA دارای سه پارامتر p، d و q است. “p” نظم رگرسیون خودکار است که به تعداد تاخیرهای متغیر مستقل برای پیش بینی اشاره دارد. ترتیب میانگین متحرک “q” اعداد خطای پیشبینی تاخیر را نشان میدهد. در نهایت، “d” برای ثابت کردن سری های زمانی استفاده می شود.
مدل های رگرسیون برای استفاده برای مسائل سری زمانی و در نتیجه برای مشکلات پیشبینی ترافیک مفید هستند. با این حال، این مدلها برای مجموعه دادههای چندبعدی غیرخطی و به سرعت در حال تغییرقابل اعتماد نیستند. نتایج باید با توجه به خطاهای پیش بینی اصلاح شوند.با این حال،بیشتر مطالعات از مدل های رگرسیون مختلف برای اعتبارسنجی مدل پیشنهادی خود استفاده کردند. با افزایش مجموعه داده ها و پیچیدگی مرتبط با آن، مدل های رگرسیون در پیش بینی تراکم ترافیک کمتر محبوب می شوند.
در حال حاضر، مدلهای رگرسیون اغلب با اصلاح با سایر الگوریتمهای یادگیری ماشین، به عنوان مثال، ANN و توابع هسته استفاده میشوند. برخی از مدلهای رگرسیون از جمله ARIMA هیبریدی در پیشبینی سرعت ترافیک برای نوع خودرو خاص، پیشبینی حجم ترافیک، و پیشبینی جریان با استفاده از ARIMA اصلاحشده استفاده میشوند.
3- درخت تصمیم
درخت تصمیم مدلی است که یک خروجی را بر اساس چندین متغیر ورودی پیش بینی می کند. دو نوع درخت وجود دارد: درخت طبقه بندی و درخت رگرسیون. هنگامی که این دو درخت ادغام می شوند، درخت جدیدی به نام درخت طبقه بندی و رگرسیون (CART) تولید می شود. درخت تصمیم از ویژگی های استخراج شده از کل مجموعه داده استفاده می کند.
جنگل تصادفی یک الگوریتم طبقهبندی ML نظارت شده است که میانگین نتایج درخت تصمیم چندگانه است. ویژگی ها به طور تصادفی در هنگام توسعه درخت های تصمیم استفاده می شوند. از تعداد زیادی درخت تصمیم گیری CART استفاده می کند. درختان تصمیم به کلاس پیش بینی شده در یک مدل جنگل تصادفی رأی می دهند.
Wang یک روش احتمالی برای پیشبینی الگوی ترافیک جادهای و ازدحام مرتبط با آن برای بخشهای جاده شهری بدون دانش قبلی در مورد مبدا و مقصد (O-D)وسیله نقلیه پیشنهاد کرد.
ین گروه سطح تراکم جاده را در سری های زمانی برای نگاشت وضعیت خودرو در شرایط ترافیکی گنجانده اند. از آنجایی که فاصله برقابلیت پیش بینی تأثیر می گذارد، طول و سرعت قطعه بهینه پیدا شد. با این حال، با داده های کمتر در دسترس، افزایش تعداد بخش ها، قابلیت پیش بینی را افزایش داد.
در مطالعهای دیگر یکی دیگر از پارامترهای ترافیک، زمان سفر، برای یافتن شاخص تراکم (CI) استفاده شد. این گروه الگوریتم جنگل تصادفی ML را برای پیش بینی وضعیت تراکم ترافیک به کار بردند. در ابتدا، آنها 100 مجموعه نمونه را برای ساخت 100 درخت تصمیم با استفاده از بوت استرپ استخراج کردند. تعداد ویژگی های ویژگی به عنوان جذر تعداد کل ویژگی ها تعیین شد.
همچنین مطالعهی دیگری از روش CART برای پیشبینی و طبقهبندی تراکم ترافیک استفاده کرد. نویسندگان از روش Moran’s I برای تحلیل همبستگی مکانی-زمانی بین جریان ترافیک شبکه جادهای مختلف استفاده کردند. مدل در مقایسه با الگوریتم SVM و K-means اثربخشی را نشان داد.
درخت تصمیم یک مدل طبقهبندی ساده حل مسئله است که میتواند برای دادههای چندویژگی اعمال شود، به عنوان مثال، در دومین مطالعهای که در این بخش اشاره شد شرایط آب و هوا، وضعیت جاده، دوره زمانی و تعطیلات به عنوان متغیرهای ورودی اعمال شدند. دانش این مدل را می توان در قالب قوانین IF-THEN نشان داد که آن را به یک مسئله قابل تفسیر تبدیل می کند.
همچنین باید در نظر داشت که نتایج طبقهبندی معمولاً باینری هستند و بنابراین در جایی که سطح ازدحام باید مشخص باشد مناسب نیستند. سایر بخشهای حملونقل، که در آن مدلهای درخت تصمیم اعمال میشود، پیشبینی ترافیک و بهینهسازی سیگنال ترافیک با منطق فازی است.
4- ماشین بردار پشتیبانی
ماشین بردار پشتیبانی (SVM) یک روش یادگیری ماشین آماری است. ایده اصلی این مدل نگاشت داده های غیرخطی به یک فضای خطی با ابعاد بالاتر است که در آن داده ها می توانند به صورت خطی توسط hyperplaneطبقه بندی شوند. بنابراین، می تواند در شناسایی الگوی جریان ترافیک برای پیش بینی تراکم ترافیک بسیار مفید باشد.
یک مطالعه سرعت سفر را در پیشبینی ازدحام بلادرنگ با استفاده از SVM تعیین کرد. آنها از Apache Storm برای پردازش داده های بزرگ با استفاده از دهانه ها و پیچ ها استفاده کردند. ترافیک، سنسورهای آب و هوا و رویدادهای جمعآوریشده از رسانههای اجتماعی نزدیک به هم توسط سیستم مورد ارزیابی قرار گرفتند. سرعت وسیله نقلیه را به کلاس هایی طبقه بندی وبه عنوان برچسب معرفی شد. افزایش داده های آموزشی دقت و زمان محاسباتی را افزایش داد. این ممکن است در نهایت پیش بینی تراکم در زمان واقعی را دشوار کند.
جریان ترافیک الگوهای مختلفی را بر اساس ترکیب ترافیک یا زمان روز نشان می دهد. SVM برای شناسایی الگوی مناسب اعمال می شود. SVM اصلاحشده در حال حاضر بیشتر کاربرد خود را در بخشهای دیگر نیز دارد، بهعنوان مثال، پیشبینی حجم ترافیک خروجی آزادراه ، پیشبینی جریان ترافیک و توسعه پایدار حملونقل و اکولوژی.
بیشتر مطالعات مدل توسعه یافته خود را با SVM مقایسه کردند .الگوریتم های یادگیری ماشین عمیق (DML) نتایج بهتری در مقایسه با SVM نشان دادند.
C. یادگیری ماشین عمیق
الگوریتمهای DML از چندین لایه پنهان برای پردازش مسائل غیرخطی تشکیل شدهاند. مهمترین مزیت این الگوریتم ها این است که می توانند بدون هیچ دانش قبلی ویژگی ها را از داده های ورودی استخراج کنند. برخلاف SML، استخراج ویژگی و آموزش مدل با هم در این الگوریتم ها انجام می شود.
DML می تواند داده های ترافیکی پیوسته و پیچیده گسترده با افق زمانی جمع آوری محدود را به الگوها یا بردارهای ویژگی تبدیل کند. از چند سال گذشته، DML در مطالعات پیشبینی تراکم ترافیک رایج شده است. مطالعات تراکم ترافیک که از الگوریتمهای DML استفاده میکنند در شکل فوق نشان داده شدهاند و در این بخش مورد بحث قرار گرفتهاند.
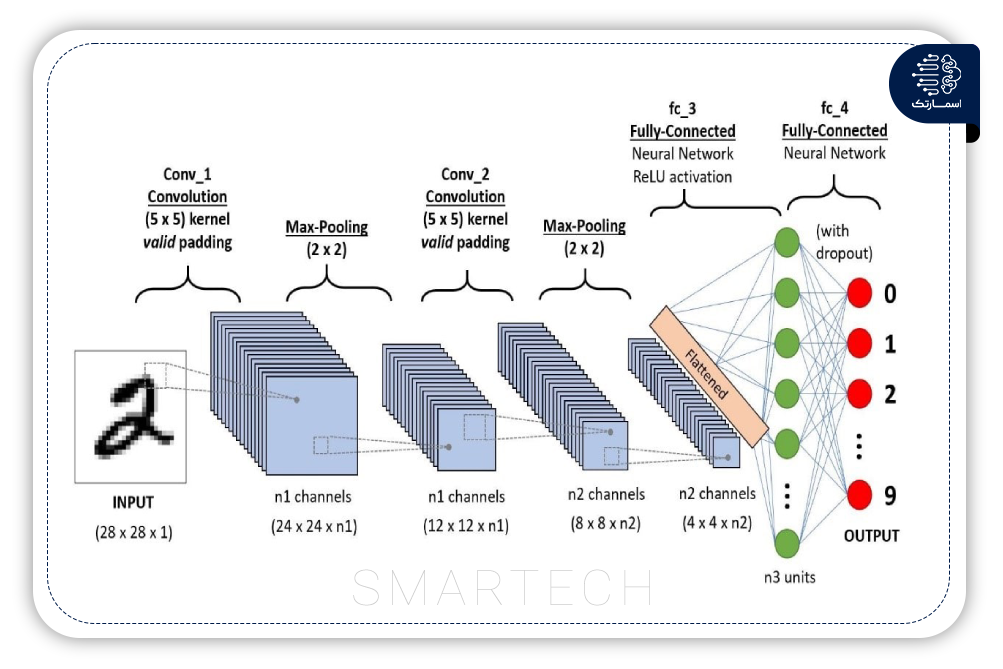
1- شبکه عصبی کانولوشنال
شبکه عصبی کانولوشنال (CNN) یک الگوریتم DML رایج در مهندسی ترافیک است. با توجه به عملکرد عالی CNN در پردازش تصویر، هنگام استفاده در پیش بینی ترافیک، داده های جریان ترافیک به یک ماتریس دو بعدی برای پردازش تبدیل می شوند. پنج بخش اصلی ساختار CNN در حمل و نقل وجود دارد: شبکه عصبی کانولوشنال (CNN) یک الگوریتم DML رایج در مهندسی ترافیک است. با توجه به عملکرد عالی CNN در پردازش تصویر، هنگام استفاده در پیش بینی ترافیک، داده های جریان ترافیک به یک ماتریس دو بعدی برای پردازش تبدیل می شوند. پنج بخش اصلی ساختار CNN در حمل و نقل وجود دارد:
لایه ورودی، لایه کانولوشن، لایه pool، لایه اتصال کامل و لایه خروجی. هر دو لایه کانولوشن و pool ویژگی های مهمی را استخراج می کنند. عمق این دو لایه در مطالعات مختلف متفاوت است. اکثر مطالعات داده های جریان ترافیک را به تصویری از یک ماتریس دو بعدی تبدیل کردند.
جایی که مجموعه داده بزرگی در دسترس است ، CNNعملکرد خوبی را نشان می دهد. همچنین دارای قابلیت یادگیری ویژگی عالی با قابلیت طبقه بندی زمانبر کمتر است. بنابراین، CNN را می توان در جایی که مجموعه داده های موجود را می توان به یک تصویر تبدیل کرد، اعمال کرد. CNN در پیشبینی سرعت ترافیک،پیشبینی جریان ترافیک و CNN اصلاحشده با LSTM نیز برای پیشبینی ترافیک اعمال میشود. با این حال هیچ استراتژی انتخاب عمق و پارامتر مدل در دسترس نیست.
2- شبکه عصبی بازگشتی
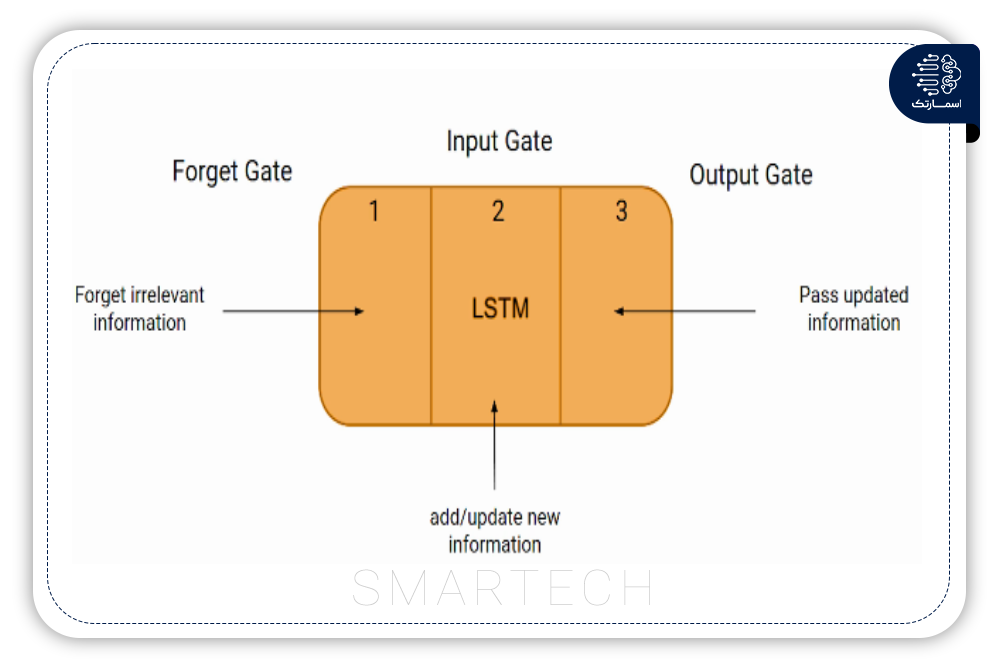
شبکه عصبی بازگشتی (RNN) با در نظر گرفتن تأثیر همسایه مرتبط، کاربرد گسترده ای در پردازش داده های ترافیکی متوالی دارد (شکل 9). حافظه کوتاه مدت طولانی (LSTM) شاخه ای از RNN است. در لایه پنهان LSTM، یک بلوک حافظه وجود دارد که شامل چهار لایه NN است که جریان اطلاعات را ذخیره و تنظیم می کند.
در سال های اخیر، با سیستم های مختلف جمع آوری داده ها با فواصل زمانی طولانی، LSTM محبوب شده است. با توجه به این مزیت، Zhao یک مدل LSTM متشکل از سه لایه پنهان و ده نورون با استفاده از دادههای بازههای طولانی توسعه داد.متخصصان ازمدل شاخص تراکم و طبقهبندی (CI-C) برای طبقهبندی ازدحام با محاسبه CI از دادههای خروجی LSTM استفاده کردند. اکثر مطالعات از فاصله مساوی CI برای تقسیم حالات تراکم استفاده می کنند. Lee،4 لایه را با 100 نورون مدل LSTM ورودی ماتریس سه بعدی اعمال کرد.عنصر ماتریس ورودی حاوی یک سرعت نرمال شده برای کوتاه کردن زمان آموزش است. Yuan-Yuan برای از بین بردن محدودیت وابستگی زمانی، مدل خود را در رویکرد یادگیری دسته ای آموزش داد. نمونه ای که از طبقه بندی مجموعه داده های آزمایشی به دست آمد برای آموزش مدل در یک چارچوب آنلاین استفاده شد.
برخی از مطالعات لایه های جدیدی را برای اصلاح مدل LSTM برای استخراج ویژگی معرفی کردند. Zhang یک لایه مکانیسم دقت بین LSTM و لایه پیش بینی معرفی کرد که استخراج ویژگی را از دنباله داده های جریان ترافیک فعال می کرد و اهمیت وضعیت ترافیک را به تصویر می کشید. Di کانولوشن معرفی کرد که ورودی مدل LSTM را برای تشکیل مدل CPM-ConvLSTM فراهم می کند.
همه مطالعات از روش one-hot برای تبدیل پارامترهای ورودی استفاده کردند. Adam، نزول گرادیان تصادفی (SGD) و شبکه حالت پژواک انتگرال نشتی (LiESN) چند روش بهینهسازی هستند که برای تنظیم دقیق نتیجه اعمال میشوند.
چند مطالعه RNN را با سایر الگوریتمها ترکیب کردند در حالی که با پارامترهای گسترده شبکه جادهها سروکار داشتند. در این رابطه Ma مدل RNN و ماشین بولتزمن محدود (RNN-RBM) را برای پیشبینی تراکم فضایی و زمانی در سراسر شبکه به کار برد. در اینجا، آنها از RBM شرطی برای ساخت معماری عمیق پیشنهادی استفاده کردند، که برای پردازش توالی زمانی با ارائه یک حلقه بازخورد بین لایه مرئی و لایه پنهان طراحی شده است.
حالت تراکم از سرعت ترافیک تجزیه و تحلیل شد و در قالب باینری در یک ماتریس به عنوان ورودی نمایش داده شد. همچنین Sun، سه لایه پنهان از RNN را با دو نوع دیگر آن ترکیب کرد: LSTM و واحد بازگشتی دردار (GRU). لایه های پنهان شامل بلوک حافظه مشخصه LSTM بود و حالت سلول و حالت پنهان توسط GRU گنجانده شد.
از آنجایی که حجم نمونه به شدت در حال افزایش است، RNN به عنوان یک روش فعلی مدلسازی محبوب میشود. RNN حافظه کوتاه مدت دارد. این مشخصه RNN به مدل سازی داده های سری زمانی غیرخطی کمک می کند. آموزش RNN نیز مستقیم است، شبیه به FNN چند لایه. با این حال، این آموزش ممکن است به دلیل تبدیل در یک معماری عمیق با چندین لایه در وابستگی طولانی مدت دشوار شود.
. در صورت مشکلات وابستگی طولانی مدت، LSTM برای استفاده مناسب تر می شود زیرا LSTM می تواند اطلاعات را برای مدت طولانی به خاطر بسپارد. RNN در سایر بخشهای حملونقل نیز کاربرد دارد، به عنوان مثال، پیشبینی جریان ترافیک ترافیک ، LSTM اصلاحشده در پیشبینی تصادف بلادرنگ ، و پیشبینی ترافیک شبکه جاده.
3- ماشین یادگیری افراطی
در سالهای اخیر، یک الگوریتم یادگیری جدید به نام ماشین یادگیری افراطی (ELM) برای آموزش شبکه عصبی پیشخور تک لایه (SLFN) پیشنهاد شده است. در ELM، وزن های ورودی و سوگیری های پنهان به جای تنظیم کامل، به طور تصادفی اختصاص داده می شوند. بنابراین آموزش ELM سریع است.
، با در نظر گرفتن این مزیت، بان و همکاران. از مدل ELM برای پیشبینی تراکم ترافیک در زمان واقعی استفاده کرد. آنها CI را با استفاده از میانگین سرعت سفر تعیین می کنند. یک اعتبارسنجی متقاطع 4 برابری برای جلوگیری از نویز در دادههای خام انجام شد. مدل بهینه گره های پنهان را از نظر هزینه محاسباتی در این مطالعه 200 نشان داد. توسعه این مطالعه توسط شن و همکاران انجام شد
شن و همکاران. با استفاده از یک مدل ماشین یادگیری افراطی نیمه نظارت شده مبتنی بر هسته (کرنل-SSELM). این مدل میتواند با مشکل دادههای بدون برچسب ELM و تأثیر دادههای ناهمگن مقابله کند. این مدل دادههای برچسبدار در مقیاس کوچک پرسنل حملونقل و دادههای ترافیک بدون برچسب مقیاس بزرگ را برای ارزیابی تراکم ترافیک شهری یکپارچه کرد. ELM زمان پردازش را سرعت بخشید، جایی که عملکرد هسته دقت و استحکام کل مدل را بهینه کرد. با این حال، جمعآوری دادههای برچسبگذاری شده در زمان واقعی از نظر منابع انسانی و زمان کاری بسیار پرهزینه بود و تعداد کارشناسان برای ارزیابی وضعیت تراکم باید بیشتر میبود.
یکی دیگر از اصلاحات EML توسط Yiming و همکاران اعمال شد.. آنها از مدل خوشه ماشین یادگیری افراطی نامتقارن (S-ELM-cluster) برای پیش بینی تراکم ترافیک کوتاه مدت با تعیین CI استفاده کردند. نویسندگان منطقه مورد مطالعه را تقسیم کردند و پردازش مدل های فرعی را به طور همزمان برای سرعت سریع پیاده سازی کردند.
مدل ELM دارای مزیت در پردازش یادگیری داده در مقیاس بزرگ با سرعت بالا است. ELM با داده های برچسب دار بهتر کار می کند. در جایی که داده های برچسب دار و بدون برچسب در دسترس هستند، ELM نیمه نظارت شده دقت پیش بینی خوبی را نشان داده است، همانطور که از مطالعات مشاهده شد. بخشهای دیگری که ELM در آنها اعمال شد شامل پیشبینی جریان ترافیک هوایی ، پیشبینی جریان ترافیک و پیشبینی فاصله حجم ترافیک بود.
به غیر از مدل هایی که قبلاً مورد بحث قرار گرفت، ژانگ و همکاران. یک مدل شبکه عصبی مبتنی بر رمزگذار خودکار عمیق با تقارن چهار لایه برای رمزگذار و رمزگشا برای یادگیری همبستگی های زمانی یک شبکه حمل و نقل پیشنهاد کرد. مؤلفه اول نمایش برداری سطوح تراکم تاریخی و همبستگی آنها را رمزگذاری می کند.
آنها سپس رمزگشایی کردند تا نمایشی از سطوح تراکم برای آینده بسازند. جزء دوم DCPS از دو لایه متراکم استفاده می کند. آنها خروجی را از رمزگشا برای محاسبه نمایش برداری از سطح تراکم تبدیل کردند. با این حال، فرآیند اطلاعات را از دست داد زیرا سطح تراکم تمام پیکسلها به طور متوسط محاسبه شد. این رویکرد نیاز به تکرار زیاد داشت و از نظر محاسباتی گران بود زیرا تمام پیکسلها بدون توجه به جادهها در نظر گرفته میشدند.
مطالعه دیگری از نسخه تعمیم یافته شبکه عصبی بازگشتی به نام شبکه عصبی بازگشتی استفاده کرد. تفاوت بین این دو در این است که در NN مکرر، وزن ها در طول توالی داده ها به اشتراک گذاشته می شوند. در حالی که NN بازگشتی یک مدل تک نورونی است. بنابراین، وزن ها در هر گره به اشتراک گذاشته می شوند.
هوانگ و همکاران از یک الگوریتم بازگشتی NN به نام شبکه حالت اکو (ESN) استفاده کرد. این مدل از یک لایه ورودی، شبکه مخزن و لایه خروجی تشکیل شده است. لایه مخزن قوانینی را می سازد که مبدا پیش بینی و افق پیش بینی را به هم مرتبط می کند. از آنجایی که مطالعه یک منطقه مطالعه بزرگ با تعداد پیوندهای وسیع را اشغال کرد، آنها پیچیدگی قوانین آموزشی را با استفاده از NN بازگشتی ساده کردند.
شکاف های بحث و تحقیق هوش مصنوعی و تراکم ترافیک
تحقیقات در زمینه پیش بینی تراکم ترافیک به طور تصاعدی در حال افزایش است.بیشتر مطالعات از دادههای سنسور/دوربین ثابت استفاده کردند. اگرچه دادههای حسگر نمیتوانند تغییر ترافیک پویا را ثبت کنند، تغییرمکرردر منبع، ارزیابی الگوهای جریان برای دادههای Probeرا پیچیده میکند.
بازه جمع آوری داده ها و وضعیت اطراف عامل مهمی در مطالعات تراکم ترافیک هستند. بازه کوچک چند روزه نمی تواند وضعیت واقعی ازدحام را به عنوان ترافیک پویا نشان دهد.عوامل محیطی مانند آبوهوا و رویدادهایی از جمله تعطیلات در ازدحام ترافیک موثرهستند.
الگوریتم یادگیری ماشین، به ویژه مدل های DML، با گذشت زمان توسعه می یابد. این نشان دهنده تأثیر واضحی بر افزایش اجرای آنها در پیش بینی تراکم ترافیک است.
الگوریتمهای استدلال احتمالی بیشتر برای بخشی از مدل پیشبینی به کار گرفته شدند که منطق فازی پرکاربردترین الگوریتم در این دسته است. از شاخه های دیگر، ANN و RNN کاربردی هستند. اکثر مطالعاتی که مدل های hybrid یا ترکیبی را به کار برده اند به کلاس یادگیری احتمالی و کمعمق تعلق دارند. تنها دو مطالعه از مدلهای یادگیری عمیق ترکیبی در حین پیشبینی تراکم شبکه استفاده کردند.
در بین تمام مدلهای DML، RNN برای پیشبینی سریهای زمانی مناسبتر است. در چند مطالعه، RNN بهتر از CNN عمل کرد زیرا شکاف بین سرعت ترافیک در کلاسهای مختلف بسیار کم بود. با این حال، به دلیل تحقیقات کمی در زمینه تراکم ترافیک، بسیاری از الگوریتمهای جدید ML هنوز به کار گرفته نشدهاند.
مدلهای SML نتایج بهتری نسبت به DML نشان دادند در حالی که تراکم ترافیک را در کوتاهمدت پیشبینی میکردند، زیرا SML میتواند خطی بودن را به طور مؤثر پردازش کند و ویژگیهای خطی سهم بیشتری در جریان ترافیک در کوتاهمدت دارند.
همه مطالعات پیشبینی کوتاهمدت مورد بحث در این مقاله با استفاده از SML نتایج امیدوارکنندهای را نشان دادند. در همان زمان، مدلهای DML دقت خوبی را نشان دادند زیرا این مدلها میتوانند هر دو ویژگی خطی و غیرخطی را به طور موثر مدیریت کنند. علاوه بر این، پیشبینی تراکم در زمان واقعی نمیتواند زمان محاسباتی بالایی را تحمل کند. بنابراین مدل هایی که زمان محاسباتی کوتاهی دارند در این مورد موثرتر هستند.
جهت گیری آینده پیش بینی تراکم ترافیک با هوش مصنوعی
پیش بینی تراکم ترافیک یک حوزه تحقیقاتی امیدوارکننده و قابل توجه در چند دهه اخیراست. زیرا با توسعه زیر ساختها هر کشوری با تراکم ترافیک مواجه است.مدلهای پیشبینی متعددی قبلاً در پیشبینی تراکم ترافیک جادهای استفاده شدهاند. با این حال، با مدلهای پیشبینی جدید توسعهیافته، زمینه بیشتری برای دقیقتر کردن پیشبینی تراکم وجود دارد.
همچنین در این عصر اطلاعات، استفاده از افزایش داده های ترافیکی موجود با استفاده از مدل های پیش بینی جدید توسعه یافته می تواند دقت پیش بینی را بهبود بخشد.مدل نیمه نظارت شده فقط برای مدل EML اعمال شد.
سایر الگوریتمهای یادگیری ماشین باید برای استفاده از دادههای برچسبدار و بدون برچسب برای دقت پیشبینی بالاتر مورد بررسی قرار گیرند. تحقیقات آتی باید بر موضوع پیشبینی تراکم ترافیک در زمان واقعی،تمرکز بر سطح تراکم ترافیک تمرکز کنند.
با توجه با تاثیرعواملی مانند آب وهوا یادگیری ماشینی به ویژه یادگیری عمیق مورد توجه قرار گرفتد. . با این حال، طیف گسترده ای از الگوریتم های یادگیری ماشین هنوز اعمال نشده است. بنابراین، فرصت گسترده ای برای تحقیق در زمینه پیش بینی تراکم ترافیک همچنان وجود دارد.

























دیدگاهتان را بنویسید