


کاربرد آمار در هوش مصنوعی

فهرست مطالب
Toggle
هوش مصنوعی (Artificial Intelligence) از دیدگاه عمومی به مجموعهای از تکنیکها و الگوریتمها اطلاق میشود که به کامپیوترها و سیستمها امکان میدهد با استفاده از دادهها و الگوها، فعالیتهایی را انجام دهند که به هوش انسانی نیاز دارد. یکی از عناصر اساسی در پیادهسازی هر سیستم هوش مصنوعی، تحلیل داده (Data Analysis) است.
دادهها در هوش مصنوعی به عنوان مادهی اولیه برای آموزش و تغذیه مدلها و الگوریتمها استفاده میشوند. در واقع، هوش مصنوعی بر اساس تحلیل و استخراج اطلاعات از دادهها، الگوها و روابط موجود در آنها، به تصمیمگیری و انجام وظایف پیچیده میپردازد. بدون دادههای کافی و مناسب، هوش مصنوعی قادر به یادگیری و ارائه پاسخهای دقیق و موثر نیست.
تحلیل داده در هوش مصنوعی شامل فرآیندهای استخراج و تمیزدهی دادهها، تفسیر و تحلیل آماری آنها، تشخیص الگوها و روابط، و ساخت و آموزش مدلها و الگوریتمها بر اساس دادهها میشود. دادهها به صورت متنوع و زیاد در اختیار هوش مصنوعی قرار میگیرند و با استفاده از تکنیکهای آماری و الگوریتمهای یادگیری ماشین، اطلاعات مفید و قابل استفاده استخراج میشوند.
بنابراین، تحلیل داده در هوش مصنوعی اساسی است و به کمک آن، ماشینها و سیستمهای هوشمند قادر به فهم و تفسیر دادههاو ارائه پاسخهای دقیق و موثر در برابر سوالات و وظایف مطرح شده خواهند بود. همچنین، تحلیل داده در هوش مصنوعی به افزایش کارایی و دقت مدلها و الگوریتمها کمک میکند و نقش بسیار مهمی در توسعه و پیشرفت این حوزه ایفا میکند
آمار در استخراج اطلاعات از دادهها نقش بسیار مهمی دارد و به عنوان ابزاری اساسی در تحلیل دادهها و استنباط نتایج قابل اعتماد استفاده میشود. اما چرا آمار در استخراج اطلاعات از داده ها اهمیت دارد؟
توصیف دادهها: آمار به ما اجازه میدهد تا دادهها را به صورت کمی و کیفی توصیف کنیم. میتوانیم میانگین، میانه، واریانس، کوچکترین و بزرگترین مقدار، توزیع، روابط بین متغیرها و سایر مشخصههای داده را با استفاده از آمار تحلیل کنیم. این اطلاعات به ما کمک میکند تا دادهها و الگوها و ویژگیهای آنها را بهتر بشناسیم و درک کنیم.
تحلیل و تفسیر دادهها: آمار به ما ابزارها و تکنیکهایی میدهد که با استفاده از آنها میتوانیم دادهها را تحلیل کنیم و نتایج قابل استنباطی را استخراج کنیم. با استفاده از آمار، میتوانیم فرضیات را تست کنیم، روابط بین متغیرها را تعیین کنیم، پیشبینیها و استنباطهایی را براساس دادهها انجام دهیم و نتایج را تفسیر کنیم.
اعتبارسنجی و قابلیت اعتماد: آمار به ما ابزارها و روشهایی میدهد تا قابلیت اعتماد و اعتبار دادهها و نتایج را بررسی کنیم. میتوانیم از آزمونهای آماری برای تعیین اینکه آیا یک الگو یا تفسیر نتیجه بهطور اتفاقی بوده یا به دلایل قابل قبولی رخ داده است، استفاده کنیم. این موضوع بسیار مهم است زیرا به ما اطمینان میدهد که نتایجی که از دادهها استنباط میشوند، قابل اعتماد و قابل قبول هستند.
انتخاب و تعیین روشهای تحلیلی: در هوش مصنوعی، با توجه به هدف و نوع دادهها، باید روشهای تحلیلی مناسب را انتخاب کنیم. آمار به ما کمک میکند تا روشهای مناسب را انتخاب کرده و دادهها را به درستی تحلیل کنیم. به عنوان مثال، اگر بخواهیم یک مدل پیشبینی بسازیم، ممکن است از روشهای آماری مانند رگرسیون لجستیک، درخت تصمیم و یا شبکههای عصبی استفاده کنیم. این روشها بر اساس تحلیل آماری دادهها، الگوها و قوانین موجود در آنها را مدل میکنند.
بنابراین، آمار در استخراج اطلاعات از دادهها به ما ابزارها و روشهایی میدهد که میتوانیم دادهها را تحلیل کرده، الگوها و روابط را شناسایی کرده و نتایج قابل اعتمادی را استخراج کنیم. با استفاده از آمار، میتوانیم تصمیمهای هوشمندانهتری در حوزه هوش مصنوعی بگیریم و بهبود عملکرد و دقت سیستمهای هوشمند را بهبود بخشید.
آمار در علم داده
مراحل علم داده
۱. تعریف مسئله: در این مرحله، مسئلهای که قرار است با استفاده از علم داده حل شود، مشخص میشود و هدفگذاری صورت میگیرد.
۲. جمعآوری داده: در این مرحله، دادههای مورد نیاز برای حل مسئله جمعآوری میشوند. این شامل انتخاب مبدأ داده، جمعآوری دادهها از منابع مختلف و ذخیره آنها میباشد.
۳. پیشپردازش داده: در این مرحله، دادههای جمعآوری شده پیشپردازش میشوند. این شامل تمیزکاری دادهها، حذف دادههای ناقص یا تکراری، تبدیل فرمتها، استخراج ویژگیها و غیره است.
۴. تحلیل داده: در این مرحله، دادهها تحلیل و بررسی میشوند تا الگوها، روابط و اطلاعات مفیدی استخراج شود. این شامل استفاده از روشهای آماری و ماشینی، انجام محاسبات و مدلسازی داده میباشد.
۵. ارزیابی مدل: در این مرحله، مدلهای ساخته شده ارزیابی میشوند تا به دقت و کارایی آنها پی ببریم. این شامل استفاده از معیارهای ارزیابی مناسب، جعلیسازی و اجرای آزمایشها بر روی دادههای نمونه میباشد.
۶. استخراج دانش: در این مرحله، اطلاعات و دانش مفیدی که از تحلیل دادهها به دست آمده استخراج میشود. این شامل تفسیر و تفاوتبخشی نتایج، استنباطها و تصمیمگیری بر اساس دادهها است.
۷. ارائه نتایج: در این مرحله، نتایج و استنباطهای به دست آمده به شکل گزارش، نمودارها، داشبوردها و غیره ارائه میشود تا به دیگران کمک کند تا درک بهتری از مسئله و راهکارهای پیشنهادی بدست آورند.
به طور کلی، علم داده یک فرآیند تکرارپذیر است و ممکن است نیاز به تغییر و بهبود مراحل داشته باشد تا به نتایج بهتر و قابل اعتمادتری برسیم

اما آمار در علم داده نقش مهمی در هر مرحله دارد. این نقش ها شامل تعریف و فهم مسئله، جمعآوری و پیشپردازش داده ، تحلیل و مدلسازی داده و تفسیر و ارائه نتایج است.
تعریف و فهم مسئله: در این مرحله، آمار به عنوان یک ابزار مهم در تحلیل و فهم دادهها و مسئله اصلی استفاده میشود. از تکنیکهای آماری میتوان برای توصیف و خلاصهسازی دادهها، توزیعهای احتمالی و میانگینگیری استفاده کرد تا بهترین رویکرد برای حل مسئله تعیین شود.
جمعآوری و پیشپردازش داده: در این مرحله میتوان از تحلیل توصیفی برای کشف الگوها و ویژگیهای داده استفاده کرد. همچنین، تکنیکهای آماری مانند آزمون فرضیه، تحلیل واریانس و همبستگی میتوانند در تحلیل ویژگیهای داده و تشخیص دادههای ناقص و نویزی کمک کنند.
تحلیل و مدلسازی داده: در این مرحله، آمار به عنوان ابزار اصلی برای ساخت و ارزیابی مدلهای پیشبینی و تحلیل دادهها استفاده میشود. توزیعهای احتمالی و روشهای استنتاج آماری میتوانند در تصمیمگیری درباره مدلها و ارزیابی کارایی آنها مفید باشند.
تفسیر و ارائه نتایج: در این مرحله، آمار به عنوان ابزاری برای تفسیر و توضیح نتایج به کار میرود. میتوان از تحلیل مقایسهای، تحلیل وابستگی و سایر تکنیکهای آماری برای توجیه و تفسیر نتایج استفاده کرد و به دیگران کمک کرد تا از مفاهیم و ارقام آماری درک بهتری داشته باشند.
به طور کلی، آمار در علم داده نقش مهمی در تحلیل، تفسیر و استنباط از دادهها ایفا میکند. از طریق استفاده از تکنیکهای آماری، میتوانیم به دقت بیشتری در درک دادهها، ساخت مدلهای قویتر و ارائه نتایج قابل اعتمادتر برسیم.
آمار چگونه داده ها را توصیف می کند؟
آمار توصیفی: از تکنیکهای آمار توصیفی مانند میانگین، میانه، حالتها، و توزیع فراوانی استفاده میشود تا ویژگیهای مختلف دادهها را مشخص کند و تصاویر کلی از دادهها را ارائه دهد.
تجزیه و تحلیل مقایسهای: با استفاده از تکنیکهای آماری مقایسهای مانند آزمون فرضیه، میتوان دادهها را بین گروهها یا دستهها مقایسه کرده و تفاوتهای معنادار را تشخیص داد.
آزمون فرضیه: از تکنیکهای آماری مانند t-آزمون و آزمون فرضیه زوجین برای تحلیل فرضیهها و تفسیر نتایج استفاده میشود. این تکنیکها به ما کمک میکنند تا بفهمیم آیا تفاوتی معنادار بین دو مجموعه داده وجود دارد یا خیر.
تحلیل واریانس: از تحلیل واریانس برای مقایسه بیش از دو گروه داده استفاده میشود. این تکنیک به ما کمک میکند تا بفهمیم آیا تفاوت معناداری بین میانگینهای گروهها وجود دارد یا خیر.
همبستگی و رگرسیون: تکنیکهای همبستگی و رگرسیون به ما کمک میکنند تا رابطه بین متغیرها را بررسی کنیم. با استفاده از این تکنیکها، میتوانیم بفهمیم که آیا دو متغیر با یکدیگر همبسته هستند و یا آیا یک متغیر میتواند به عنوان پیشبینیکننده برای متغیر دیگر استفاده شود.
نمودارها و نمایشگرها: استفاده از نمودارها و نمایشگرها میتواند به ما کمک کند تا الگوها وروابط دادهها را به صورت بصری درک کنیم. نمودارهایی مانند نمودار میلهای، نمودار نقطهای، نمودار دایرهای و نمودار جعبهای میتوانند انواع مختلفی از دادهها را نمایش دهند و به تحلیل و تفسیر دادهها کمک کنند.
اعتبارسنجی: استنتاج آماری میتواند به ما کمک کند تا اعتبار نتایج را بررسی کنیم. با استفاده از تکنیکهایی مانند بازه اطمینان، میتوانیم مطمئن شویم که نتایج ما قابل اطمینان هستند و به چه اندازه دقیق هستند.
آزمون فرضیه و تحلیل رگرسیون در هوش مصنوعی
آزمون فرضیه و تحلیل رگرسیون دو تکنیک مهم در حوزه هوش مصنوعی هستند که در تحلیل دادهها و پیشبینی رفتارها استفاده میشوند. در زیر به توضیح این دو تکنیک میپردازیم:
آزمون فرضیه:
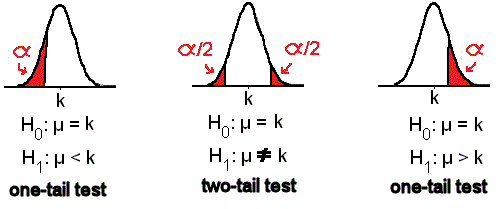
در هوش مصنوعی، آزمون فرضیه برای ارزیابی صحت یا نادرست بودن فرضیات و فرضیههایی که در مورد دادهها و روابط بین متغیرها مطرح میشوند، استفاده میشود. در آزمون فرضیه، دو فرضیه اصلی وجود دارد: فرضیه صفر (H0) و فرضیه جایگزین (H1).
فرضیه صفر (H0): این فرضیه بیان میکند که هیچ تفاوت یا ارتباط معناداری بین متغیرها وجود ندارد یا مقداری خاص برای پارامتری مشخص نداریم.
فرضیه جایگزین (H1): این فرضیه معکوس فرضیه صفر است و بیان میکند که تفاوت یا ارتباط معناداری بین متغیرها وجود دارد یا مقداری خاص برای پارامتری مشخص است.
برای آزمون فرضیه، ابتدا فرضیه صفر و فرضیه جایگزین تعریف میشود. سپس با استفاده از روشهای آماری مانند آزمون t، آزمون F و آزمون χ²، دادهها بررسی میشوند تا ببینیم آیا میتوانیم فرضیه صفر را رد کنیم و به فرضیه جایگزین پذیرفته شود یا خیر. اگر نتیجه آزمون نشان دهد که فرضیه صفر رد میشود، به این معنی است که متغیرها یا روابط بین متغیرها معنادار هستند و فرضیه جایگزین قابل قبول است.
تحلیل رگرسیون:
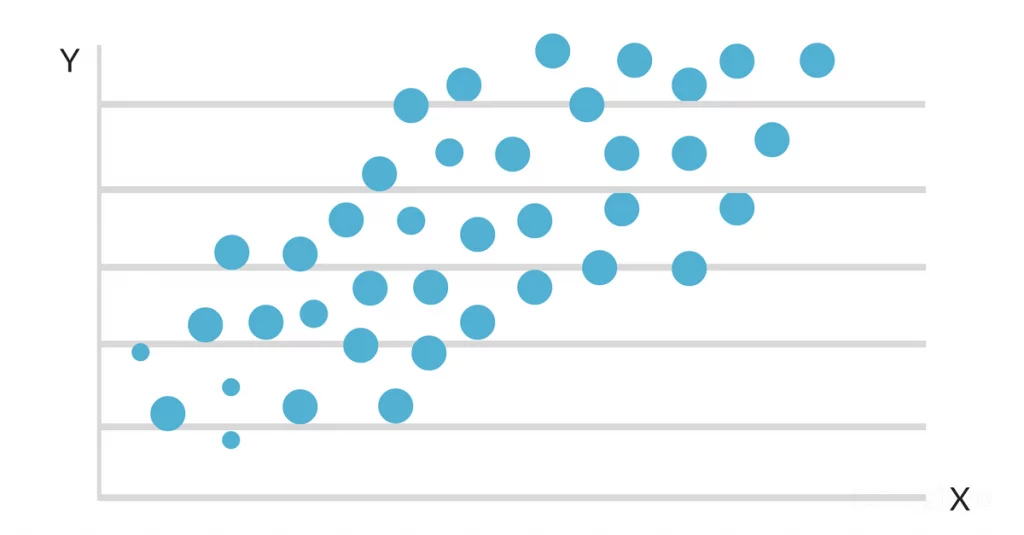
تحلیل رگرسیون یک روش آماری است که برای بررسی رابطه بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود. در هوش مصنوعی، تحلیل رگرسیون میتواند به تخمین و پیشبینی رفتارها و ویژگیها بر اساس متغیرهای مستقل کمک کند.
در تحلیل رگرسیون، متغیر وابسته (متغیری که میخواهیم پیشبینی کنیم) و متغیرهای مستقل (متغیرهایی که احتمالاً تأثیری بر متغیر وابسته دارند) تعریف میشوند. سپس با استفاده از روشهای مختلفی مانند رگرسیون خطی، رگرسیون لجستیک، رگرسیون چندجملهای و غیره، رابطه بین متغیرهای مستقل و وابسته مدل میشود.
یک تحلیل رگرسیون میتواند پارامترهای مدل را تخمین بزند و اهمیت نسبی متغیرهای مستقل را در توضیح و پیشبینی متغیر وابسته نشان دهد. برای ارزیابی کیفیت مدل رگرسیون، از معیارهایی مانند ضریب تعیین (R-squared)، خطای متوسط مطلق (MAE)، خطای متوسط مربعات (MSE) و غیره استفاده میشود.
تحلیل رگرسیون در هوش مصنوعی به طور گسترده ای در زمینه های مختلفی مانند پیشبینی و تحلیل بازدهی مالی، پیشبینی خریداران، تحلیل تأثیر عوامل در سیستمهای پیچیده، تحلیل دادههای پزشکی و غیره استفاده میشود.
به طور خلاصه، آزمون فرضیه و تحلیل رگرسیون دو تکنیک مهم در هوش مصنوعی هستند که برای بررسی و پیشبینی روابط و الگوهای موجود در دادهها استفاده میشوند. آزمون فرضیه برای ارزیابی صحت فرضیهها و تحلیل رگرسیون برای مدلسازی و پیشبینی رفتارها استفاده میشوند.
استفاده از آمار در یادگیری ماشین
یادگیری ماشین یک زیرشاخه از هوش مصنوعی است که به بررسی روشها و الگوریتمهایی میپردازد که به ماشینها امکان یادگیری از دادهها و بهبود عملکرد خود را بدون نیاز به برنامهریزی صریح میدهد. در یادگیری ماشین، مدلها و الگوریتمها طراحی میشوند تا بتوانند از دادهها یاد بگیرند و با استفاده از آنها پیشبینیها، تصمیمگیریها و وظایف دیگر را انجام دهند.
استفاده از دادهها در یادگیری ماشین بسیار حائز اهمیت است. دادهها به عنوان منبع اصلی آموزش و تجربه برای مدلهای یادگیری ماشین عمل میکنند. در فرایند یادگیری، دادهها به مدل معرفی میشوند و مدل با تحلیل و استخراج اطلاعات از دادهها، الگوها و قواعد را یاد میگیرد.
دادهها میتوانند به صورت مجموعههای بزرگی از نمونهها (نمونههای آموزش) باشند که هر کدام شامل ویژگیها یا ورودیهایی است که مدل باید از آنها یاد بگیرد. به همراه هر نمونه، برچسب (برای دستهبندی) یا یک مقدار هدف (برای پیشبینی) نیز وجود دارد. هدف از استفاده از دادهها در یادگیری ماشین، آموزش یا تنظیم مدل به گونهای است که بتواند در مواجهه با دادههای جدید، پاسخهای صحیح و قابل قبولی را تولید کند.
مراحل اصلی در استفاده از دادهها در یادگیری ماشین عبارتند از:
1.جمعآوری دادهها: این مرحله شامل جمعآوری و تهیه دادههای مورد نیاز برای آموزش مدل است. دادهها میتوانند از منابع مختلف مانند پایگاه دادهها، سنسورها، اینترنت و غیره جمعآوری شوند.
2.پیشپردازش دادهها: در این مرحله، دادهها بررسی، تمیز شده و به شکلی آماده برای استفاده در مدلهای یادگیری ماشین قرار میگیرند. این مرحله شامل حذف دادههای ناقص یا تکراری، تبدیل ویژگیها به فرمت مناسب، نرمالسازی دادهها و استخراج ویژگیهای مهم میشود.
3.انتخاب مدل: در این مرحله، مدل یادگیری ماشین مناسب برای مسئله مورد نظر انتخاب میشود. مدلهای مختلفی مانند شبکههای عصبی مصنوعی، درخت تصمیم، ماشین بردار پشتیبان و سایر الگوریتمهای یادگیری ماشین در اینجا استفاده میشوند.
4.آموزش مدل: در این مرحله، مدل با استفاده از دادههای آموزش، آموزش داده میشود. به عبارت دیگر، مدل بهینهسازی میشود تا بتواند الگوها و روابط بین ورودیها و خروجیها را یاد بگیرد.
5.ارزیابی مدل: پس از آموزش مدل، نیاز است که عملکرد آن بر روی دادههای آزمون یا دادههای جدید ارزیابی شود. این مرحله به ما کمک میکند تا میزان دقت و عملکرد مدل را ارزیابی کنیم و در صورت نیاز بهبودهای لازم را اعمال کنیم.
6.استفاده از مدل: پس از آموزش و ارزیابی، مدل آماده استفاده در محیطهای واقعی میشود. مدل میتواند برای پیشبینی، تصمیمگیری، دستهبندی و سایر وظایف مورد استفاده قرار گیرد.
استفاده از دادهها در یادگیری ماشین باعث میشود تا مدلها بتوانند الگوهای پنهان و قواعد از دادهها استخراج کنند و باعث بهبود عملکرد و قابلیتهای پیشرفتهتری در ماشینها شوند. در عصر اطلاعات و دادههای بزرگ، استفاده بهینه از دادهها در یادگیری ماشین از اهمیت بسیاری برخوردار است و در حوزههای گوناگونی مانند پزشکی، تجارت، رباتیک، خودروسازی و بسیاری موارد دیگر مورد استفاده قرار میگیرد.
الگوریتمهای آماری در یادگیری ماشین به عنوان یکی از روشهای اصلی و پایهای استفاده میشوند. این الگوریتمها بر اساس اصول و تکنیکهای آماری و احتمالاتی عمل میکنند و در فرایند یادگیری و پیشبینی بر اساس دادهها استفاده میشوند. در زیر به برخی از معروفترین الگوریتمهای آماری در یادگیری ماشین اشاره می شود:
رگرسیون خطی (Linear Regression): این الگوریتم برای مسائل پیشبینی مقادیر پیوسته استفاده میشود. با استفاده از روش کمترین مربعات، رابطهای خطی بین ورودیها و خروجیها تعیین میشود. این رابطه میتواند برای پیشبینی مقادیر جدید استفاده شود.
الگوریتم کی-نزدیکترین همسایه (k-Nearest Neighbors – kNN): در این الگوریتم، برای دستهبندی دادهها، از شباهت و فاصله بین نمونهها استفاده میشود. با تعیین یک تعداد k، نزدیکترین k نمونه به نمونه جدید شناسایی میشوند و بر اساس برچسبهای آنها، برچسب نمونه جدید تعیین میشود.
ماشین بردار پشتیبان (Support Vector Machines – SVM): این الگوریتم برای دستهبندی و رگرسیون استفاده میشود. SVM به دنبال یافتن یک صفحه یا هایپرپلان در فضای ویژگی است که بین دو دسته دادهها قرار میگیرد و فاصله کمینه بین دادهها و صفحه را حفظ میکند.
ناحیهبندی گاوسی (Gaussian Mixture Models – GMM): این الگوریتم برای مدلسازی توزیع احتمالاتی دادهها و کاوش کلاسترها استفاده میشود. با استفاده از ترکیب چندین توزیع گاوسی، ناحیهبندی بر روی دادهها انجام میشود.
شبکههای عصبی (Neural Networks): شبکههای عصبی به عنوان یک الگوریتم قدرتمند در یادگیری ماشین مورد استفاده قرار میگیرند. این الگوریتمها بر اصول عصبشناسی مغز بنا شدهاند و شامل لایههای مختلف از نورونها است که از طریق وزنها، ارتباطبین ورودیها و خروجیها را یاد میگیرند. شبکههای عصبی میتوانند در مسائل دستهبندی، رگرسیون، تشخیص الگو و ترجمه ماشینی موثر باشند.
این الگوریتمها تنها چند نمونه از الگوریتمهای آماری در یادگیری ماشین هستند. هر الگوریتم دارای قابلیتها، محدودیتها و مناسبیتهای خاص خود است. انتخاب الگوریتم متناسب با مسئله و نوع دادهها بسیار مهم است تا بهترین نتایج را بتوان به دست آورد.
استفاده از آمار در شبکه های عصبی
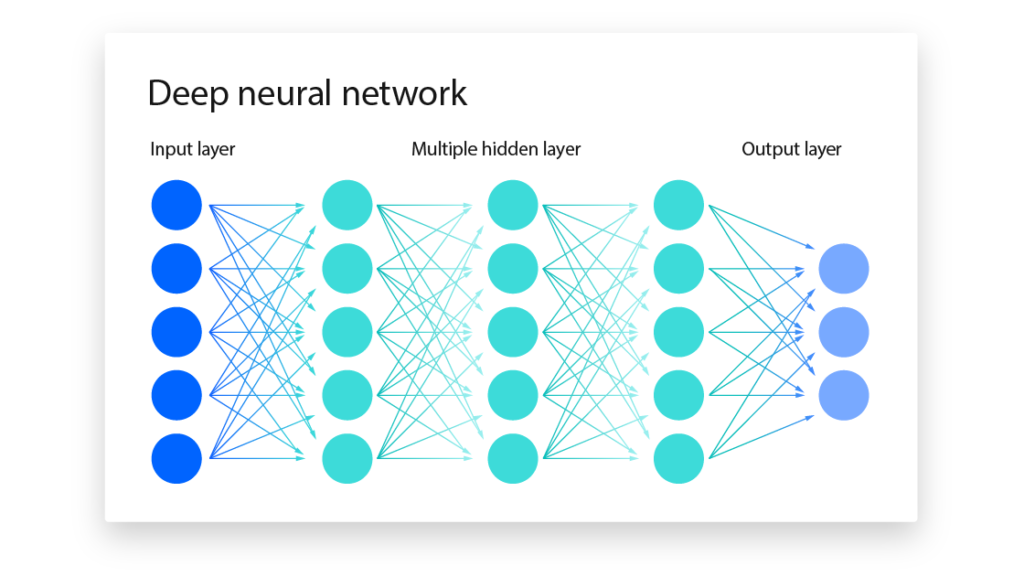
شبکههای عصبی (Neural Networks) ساختارهایی هستند که بر اساس اصول عصبشناسی مغز انسان بنا شدهاند. این سیستم از شمار زیادی عناصر پردازشی بهم پیوسته به نام نورونها تشکیل شده اند که برای حل یک مسئله با یکدیگر هماهنگ می شوند. یک شبکه عصبی برای انجام وظیفههای مشخص مانند شناسایی الگوها و دسته بندی اطلاعات، زمان یاد گیری تنظیم میشود
روشهای آماری مرتبط با شبکههای عصبی عبارتند از:
تابع فعالسازی (Activation Function): تابع فعالسازی در شبکههای عصبی برای تعریف رفتار نورونها استفاده میشود. این تابع ورودی را به خروجی تبدیل میکند و عملکرد غیرخطی به شبکهها میبخشد. برخی از توابع فعالسازی معروف شامل تابع سیگموید، تابع ReLU و تابع تانژانت هایپربولیک میباشند.
الگوریتم پسانتشار خطا (Backpropagation): این الگوریتم در فرایند آموزش شبکههای عصبی استفاده میشود. با استفاده از این الگوریتم، خطا وارده در خروجی شبکه به عقب برمی گردد و وزنها به گونهای تنظیم میشوند که خطا به کم ترین حد خود برسد. این فرایند به صورت تکراری انجام میشود تا شبکه بهترین عملکرد را بر روی دادههای آموزشی نشان دهد.
تابع هزینه (Cost Function): تابع هزینه در شبکههای عصبی برای اندازهگیری خطا بین خروجی تخمینی شبکه و مقدار واقعی بکار میرود. هدف اصلی در آموزش شبکه، کم کردن مقدار تابع هزینه است. برخی از توابع هزینه شامل خطا میانگین مربعات (Mean Squared Error) و آنتروپی متقاطع (Cross-Entropy) هستند.
روشهای بهینهسازی (Optimization Methods): در آموزش شبکههای عصبی، از روشهای بهینهسازی برای بهبود وزنها و کم کردن تابع هزینه استفاده میشود. مثالهایی از روشهای بهینهسازی شامل کاهش گرادیان (Gradient Descent)، نسخه بهبود یافلی (Improved versions) مانند Momentum، RMSprop، Adam و AdaGrad میباشند. این روشها با تنظیم مقدار وزنها بر اساس مقدار گرادیان و تغییرات آن، به شبکه کمک میکنند تا بهترین نقطه بهینه را در فضای وزنها پیدا کند.
روشهای انتقال دانش (Transfer Learning): این روشها مرتبط با استفاده از شبکههای عصبی پیشآموزشدیده بر روی مسائل مشابه هستند. با استفاده از شبکههایی که بر روی مجموعهدادههای بزرگ و متفاوت آموزش دیدهاند، میتوان بخشی از اطلاعات وزنها و ارتباطات را به مسئله جدید منتقل کرده و فرایند آموزش را سریعتر و با کیفیتتر انجام داد.
این تنها چند مورد از روشهای آماری مرتبط با شبکههای عصبی هستند. این روشها به شکل ترکیبی در فرایند آموزش، بهینهسازی و ارزیابی شبکههای عصبی استفاده میشوند تا بهترین نتایج و عملکرد را در مسائل یادگیری ماشین به دست آورند.
استفاده از آمار در پردازش زبان طبیعی
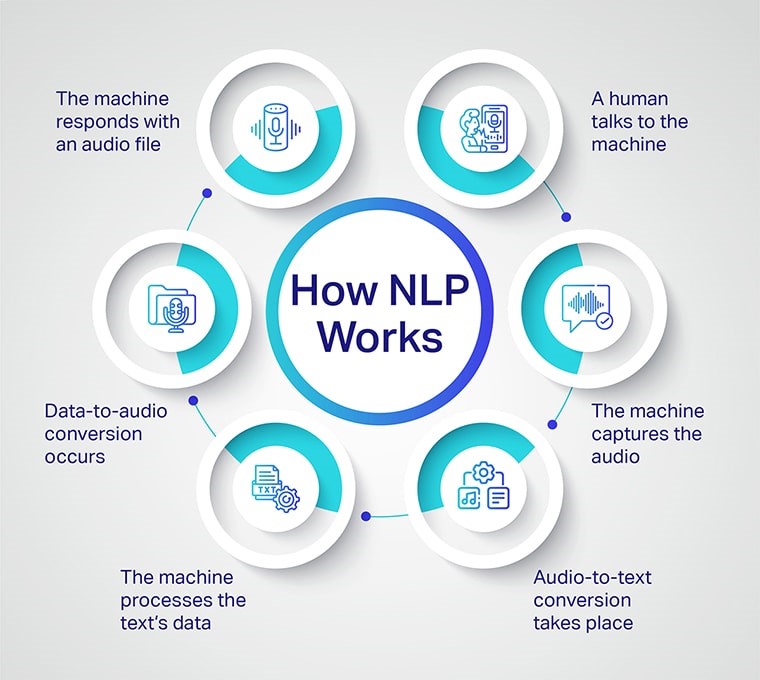
پردازش زبان طبیعی (Natural Language Processing یا NLP) شاخهای از هوش مصنوعی که به بررسی و تفسیر زبان طبیعی انسان میپردازد. هدف اصلی NLP، تفاهم و برقراری تعامل بین انسان و سیستمهای کامپیوتری به زبان طبیعی است
آمار در پردازش زبان طبیعی و تحلیل متن نقش مهمی ایفا میکند. برخی از کاربردهای آمار در این حوزه شامل:
تحلیل فرکانس و توزیع کلمات: با استفاده از آمار، میتوانیم توزیع و فراوانی کلمات در یک متن را بررسی کنیم. این کاربرد به ما کمک میکند تا الگوها و قوانین زبانی را بشناسیم. مثلاً میتوانیم بررسی کنیم که کدام کلمات در یک متن علمی بسیار استفاده میشوند یا کدام کلمات اغلب در یک متن اخباری ظاهر میشوند.
مدلسازی زبانی: آمار در مدلسازی زبانی نقش کلیدی دارد. مدلهای زبانی میتوانند احتمال وقوع یک سری کلمات بعدی را بر اساس کلمات قبلی محاسبه کنند. این مدلها معمولاً بر پایه آماریهایی مانند مدل زبانی n-گرم (n-gram) و مدل زبانی پنجهای (Pentagram) ساخته میشوند.
تحلیل احساسات و استخراج اطلاعات: در تحلیل متن، آمار میتواند در تشخیص و تحلیل احساسات و نظرات متنی مفید باشد. مثلاً با استفاده از آمار، میتوانیم اموجی ها و کلماتی که به احساسات اشاره میکنند (مثل “خوب” و “بد”) را شمارش کنیم و بر اساس آنها، احساسات مثبت یا منفی یک متن را تشخیص دهیم.
تحلیل و تفسیر متن: آمار در تحلیل و تفسیر متن نیز بکار میرود. میتوان با استفاده از آمار، الگوها، تکرارها، و توالیهای خاص کلمات را شناسایی کرده و به دست آوردن اطلاعات مهم از متن کمک کند. به عنوان مثال، میتوان با استفاده از تحلیل آماری تشخیص داد که چه کلماتی اغلب با یکدیگر در یک متن بیایند و از آنجا به عنوان عبارات ثابت استفاده شوند.
تجزیه و تحلیل موضوعی: آمار در تجزیه و تحلیل موضوعی متون نقش مهمی دارد. با فرض اینکه دارید با یک مجموعه بزرگ از متنها کار میکنید و میخواهید موضوعات مختلفی که در آنها به تفصیل صحبت شده است را شناسایی کنید. با استفاده از آمار، میتوانید کلمات مهم در هر متن را شمارش کنید و سپس با تحلیل توزیع آنها در متنها، موضوعات اصلی را تشخیص دهید. به عنوان مثال، با تجمیع کلمات مرتبط با ورزش و تحلیل توزیع آنها در متنها، میتوانید به موضوع ورزشی اشاره کنید.
به طور کلی، آمار در پردازش زبان طبیعی و تحلیل متن به ما کمک میکند تا الگوها، قوانین زبانی، احساسات، موضوعات و اطلاعات مهم را از متنها استخراج کنیم. این اطلاعات میتواند در بسیاری از زمینهها مانند جستجوی اطلاعات، خلاصه سازی متن، تحلیل احساسات و تشخیص خبر جعلی مفید باشد.
مدلهای آماری در پردازش زبان طبیعی (NLP) مدلهایی هستند که بر اساس آمار و احتمالات، قوانین زبانی و الگوهای زبانی را مدلسازی میکنند. این مدلها برای بسیاری از وظایف NLP مورد استفاده قرار میگیرند. در زیر به برخی از مدلهای آماری معروف در NLP اشاره میکنم:
مدل زبانی N-گرم (N-gram): این مدلها بر اساس توالیهای متوالی از N کلمه در یک زبان، احتمال وقوع کلمه بعدی را مدلسازی میکنند. به عنوان مثال، در مدل زبانی دوگرم (Bigram)، احتمال وقوع یک کلمه بعدی بر اساس کلمه قبلی محاسبه میشود. این مدلها به صورت ساده و سریع قابل پیادهسازی هستند، اما معمولاً به توالیهای طولانیتر و مفهومیتر در زبان توجه نمیکنند.
مدل زبانی پنجهای (Pentagram): این مدلها بر اساس توالیهای پنج کلمه در یک زبان، احتمال وقوع کلمه بعدی را مدلسازی میکنند. این مدلها نسبت به مدلهای N-گرم پیچیدهتر هستند و قادرند توالیهای طولانیتر و معناییتر را مدلسازی کنند. با این حال، پیادهسازی و آموزش این مدلها نیازمند مجموعه دادههای بزرگتر و محاسبات بیشتر است.
مدل زبانی مبتنی بر شرط (Conditional Language Model): این مدلها به توزیع شرطی کلمه بعدی بر اساس یک شرط، مانند کلمه یا جمله قبلی، توجه میکنند. این مدلها معمولاً در وظایفی مانند ترجمه ماشینی، تولید متن و تولید پاسخ به سوالات استفاده میشوند.
مدل زبانی بافتی (Contextual Language Model): این مدلها سعی میکنند توالیهای کلمات را با در نظر گرفتن بافت آنها مدلسازی کنند. مدلهای زبانی بافتی معمولاً از شبکههای عصبی بازگشتی (Recurrent Neural Networks، به اختصار RNN) یا مدلهای زبانی بافتی مبتنی بر ترنسفورمر (Transformer-based ContextualLanguage Models) مانند مدل GPT استفاده میکنند. این مدلها قادرند به درک و تولید متن با توجه به بافت و مفهوم جملات قبلی و بعدی بپردازند و معمولاً در وظایفی مانند ترجمه ماشینی، خلاصهسازی، پرسش و پاسخ و تولید متن خلاق استفاده میشوند.
مدلهای آماری در NLP از قدرت مدلسازی توزیعهای زبانی بهره میبرند و معمولاً با استفاده از الگوریتمهای آموزشی مانند ماشینهای بردار پشتیبان (Support Vector Machines)، یادگیری ماشینی عمیق (Deep Learning) و غیره آموزش داده میشوند. با پیشرفت تکنولوژی و استفاده از مدلهای نیمه آماری و عمیق، بهبود قابل توجهی در کیفیت و دقت پردازش زبان طبیعی حاصل شده است.
آمار در حوزه بینایی ماشین
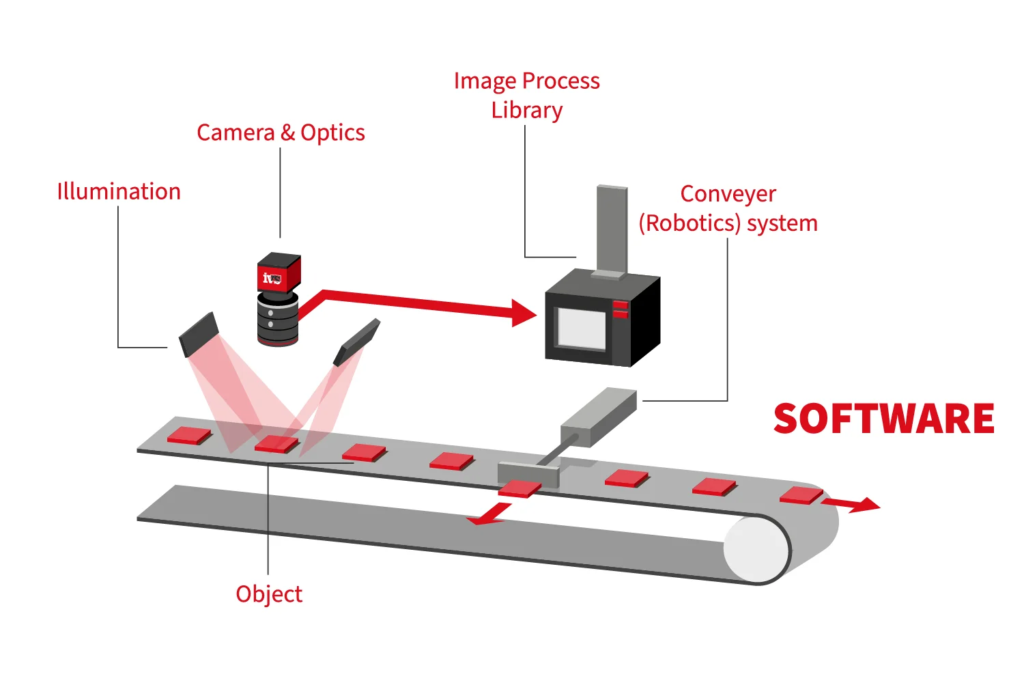
آمار و تشخیص الگو در حوزه بینایی ماشین (Computer Vision) نقش مهمی را ایفا میکنند. در زیر به برخی از کاربردهای آمار در بینایی ماشین و تشخیص الگو اشاره میکنیم:
تصویرسازی و فیلترینگ: در بینایی ماشین، از تکنیکهای فیلترینگ استفاده میشود تا الگوهای خاصی در تصاویر را استخراج کند. این فیلترها میتوانند بر اساس آمارهای مختلفی مانند میانگین، واریانس، هیستوگرام و غیره طراحی شوند. به عنوان مثال، فیلتر گوسی برای حذف نویز در تصاویر از توزیع گوسی استفاده میکند.
تشخیص الگو و تطبیق الگو: در بینایی ماشین، کاربرد آمار در تشخیص الگو و تطبیق الگو بسیار مهم است. الگوریتمهای تشخیص الگو معمولاً بر اساس مدلهای آماری مانند مدلهای شرطی، مدلهای نمایی یا مدلهای گرافی استفاده میکنند. این مدلها میتوانند الگوهایی را که در تصاویر تکرار میشوند، شناسایی کنند. به عنوان مثال، در تشخیص چهره، از مدلهای آماری مبتنی بر اجزای چهره برای تشخیص و تطبیق الگو استفاده میشود.
تصویربرداری و تجزیه و تحلیل تصاویر: در بینایی ماشین، آمار و تحلیل آماری میتواند در تصویربرداری و تجزیه و تحلیل تصاویر مورد استفاده قرار بگیرد. این مدلها میتوانند توزیعهای آماری مربوط به تصاویر را مدلسازی کنند و از آنها برای تشخیص ویژگیها و الگوهای خاص استفاده کنند. به عنوان مثال، در تجزیه و تحلیل تصاویر پزشکی، آمار میتواند برای توصیف و تحلیل خواص ساختاری و رنگی تصاویر استفاده شود.
طبقهبندی و تشخیص الگوهای پیچیده: در بینایی ماشین، آمار و تشخیص الگو میتواند در طبقهبندی تصاویر و تشخیص الگوهای پیچیده مانند تشخیص اشیاء، تشخیص چهره، تشخیص علامتها و غیره مورد استفاده قرار گیرد. در واقع، آمار به عنوان یک ابزار قدرتمند در تحلیل تصاویر و تشخیص الگوها در بینایی ماشین استفاده میشود. اگر بخواهیم به طور کلی در مورد کاربردهای آمار در این حوزه صحبت کنیم، میتوانیم به موارد زیر اشاره کنیم:
استخراج ویژگیها: آمار به کمک روشهای مختلفی مانند هیستوگرام، میانگین، واریانس و کوواریانس، میتواند ویژگیهای مهم تصاویر را استخراج کند. این ویژگیها میتوانند برای توصیف و تمایز اشیاء و الگوهای مختلف استفاده شوند.
طبقهبندی: آمار به عنوان یک ابزار مهم در طبقهبندی تصاویر مورد استفاده قرار میگیرد. با استفاده از روشهای آماری مانند بیزین، ماشین بردار پشتیبان (SVM) و شبکههای عصبی، میتوان تصاویر را به دستههای مختلفی تقسیم بندی کرد و آنها را طبقهبندی کرد.
تشخیص الگو: آمار در تشخیص الگوها نقش مهمی ایفا میکند. با استفاده از روشهای آماری مانند مدلهای شرطی، مدلهای نمایی و مدلهای گرافی، میتوان الگوهای خاصی را در تصاویر تشخیص داد. به عنوان مثال، در تشخیص چهره، از مدلهای آماری برای تشخیص و تطبیق الگو استفاده میشود.
تجزیه و تحلیل تصاویر: آمار و تجزیه و تحلیل آماری میتواند در تحلیل تصاویر و توصیف خواص ساختاری و رنگی آنها مورد استفاده قرار بگیرد. با استفاده از آمار، میتوان توزیعهای آماری مربوط به تصاویر را مدلسازی کرده و از آنها برای تشخیص ویژگیها و الگوهای خاص استفاده کرد.
در حوزه بینایی ماشین، روشهای آماری برای تحلیل و استخراج اطلاعات از تصاویر و ویدیوها استفاده میشوند. این روشها بر اساس مفاهیم و تکنیکهای آماری متنوعی که در زمینه تحلیل دادهها و الگوریتمهای یادگیری ماشین استفاده میشوند، طراحی و پیادهسازی میشوند. در ادامه به برخی از مهمترین روشهای آماری در بینایی ماشین اشاره میکنم:
مدلهای گرافی احتمالاتی: در بینایی ماشین، مدلهای گرافی احتمالاتی مانند شبکههای مارکف مونت کارلو (MCMC) و شبکههای بیزی که بر پایه نظریه احتمال و آمار قرار دارند، استفاده میشوند. این مدلها برای برآورد و تخمین پارامترها و حالتهای مخفی در فرآیندهای تصادفی و تفسیر تصاویر با استفاده از اطلاعات آماری و احتمالاتی مناسب به کار میروند.
مدلهای مخفی مارکف: مدلهای مخفی مارکف (HMM) در بینایی ماشین برای مدلسازی فرآیندهای تصادفی مخفی استفاده میشوند. این مدلها به خصوص در حوزه تشخیص و توصیف حالتهای مختلف تصاویر، مانند تشخیص حالت وضعیت یک شیء در یک تصویر، استفاده میشوند. الگوریتم Viterbi که بر پایه مفهوم آماری احتمالات است، برای استنتاج و پیشبینی سریهای زمانی نیز استفاده میشود.
مدلهای یادگیری ماشین: در بینایی ماشین، الگوریتمهای یادگیری ماشین مبتنی بر روشهای آماری بسیار محبوب هستند. این الگوریتمها، مانند شبکههای عصبی کانولوشنی (CNN)، مدلهای گرافیکی تصادفی (Random Forests) و ماشینهای بردار پشتیبان (SVM)، برای تشخیص الگوها، تصاویر، شناسایی و طبقهبندی اشیاء، تشخیص چهره و دستهبندی تصاویر استفاده میشوند.
روشهای تجمعی و توزیعهای آماری: در بینایی ماشین، روشهای تجمعی و توزیعهای آماری مورد استاستفاده قرار میگیرند. این روشها شامل تکنیکهای مانند هیستوگرامسازی، تخمین توزیعها (مانند تخمین توزیع گاوسی)، تجزیه تجمعی و توزیعهای تجمعی (مانند کوانتیلها و میانگین) میشوند. این روشها برای توصیف و تحلیل ویژگیها و دادههای تصاویر و استخراج اطلاعات آماری مفید استفاده میشوند.
روشهای تفاضلی و آزمون فرضیه: در بینایی ماشین، روشهای تفاضلی و آزمون فرضیه برای تحلیل و بررسی تفاوتها و مقایسه عملکرد الگوریتمها و مدلها مورد استفاده قرار میگیرند. با استفاده از آزمونهای آماری مختلف، میتوان تفاوتها را در عملکرد الگوریتمها مورد بررسی قرار داد و قضاوت آماری درباره تفاوت معنادار آنها ارائه داد.
خلاصه
آمار در هوش مصنوعی نقش بسیار حساس و کلیدی دارد . درهوش مصنوعی داده از اهمیت خاصی برخوردار است زیرا دادهها در هوش مصنوعی به عنوان مادهی اولیه برای آموزش و تغذیه مدلها و الگوریتمها استفاده میشوند بنابراین، تحلیل داده در هوش مصنوعی اساسی است و آمار در استخراج اطلاعات از دادهها نقش بسیار مهمی دارد به طور مثال در یادگیری ماشین از روشهای آماری مانند رگرسیون خطی، شبکههای عصبی، مدلهای گرافی احتمالاتی و ماشینهای بردار پشتیبان برای آموزش مدلهای یادگیری ماشین از دادهها استفاده میشوند.













دیدگاهتان را بنویسید